通过大语言模型理解电信语言
论文分享
GenAINet通信大模型
人工智能 (AI) 的最新进展为电信网络设计、实施和部署中涉及的许多自动化任务开辟了新的领域。大型语言模型 (LLM) 的出现,进一步推动了这一趋势,人们认为LLM是实现自治、交互式 AI 代理的基石。在此背景下,阿联酋技术创新研究所的研究人员和哈里发大学的Mérouane Debbah教授团队研究了LLM在电信领域的应用。用电信领域语言对 BERT、蒸馏 BERT (DistilBERT)、RoBERTa 和 GPT-2 在内的多个 LLM模型进行微调,并演示了用于识别第三代合作伙伴项目 (3GPP) 标准工作组的用例。实验结果表明,这些模型可以有效识别电信语言的类别。
Understanding Telecom Language Through Large Language Models
Lina Bariah1, Hang Zou1, Qiyang Zhao1,
Belkacem Mouhouche1, Faouzi Bader1, Merouane Debbah2
1Technology Innovation Institute, Abu Dhabi, UAE
2Khalifa University, Abu Dhabi, UAE
原文链接:
https://ieeexplore.ieee.org/document/10437725
论文版权归属IEEE版权方,本文分享仅用于技术交流,未经许可禁止用于商业用途。
1. 用于电信语言分类的LLMs:
本文中,作者使用了 BERT、DistilBERT、RoBERTa、GPT-2 语言模型作为基础模型,使用单任务单标签微调方法进行微调,用来完成3GPP Tdoc分类任务,流程如图1所示。微调模型能够识别与 3GPP 蜂窝架构类别相关的特定技术文本,即无线接入网络 (RAN)、系统架构 (SA) 或核心网络和终端 (CT)。微调过程的参数细节和数据预处理方法请见原文。
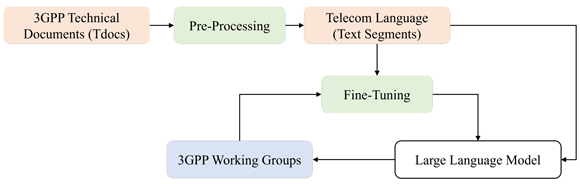
图1. 3GPP技术语言微调LLM的流程
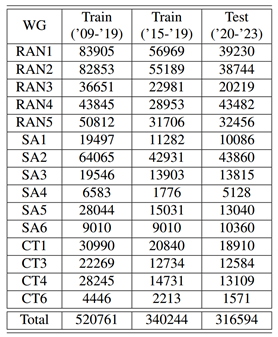
表Ⅰ. 不同工作组和不同年份的 3GPP Tdoc 文件
3. 实验验证和结果:
作者将3GPP Tdoc分为训练、验证和测试数据集,用来对LLM进行微调。图2展示了使用2015 年至 2019 年3GPP 文件微调的不同 LLM 在分类精度方面的性能。可以观察到所有模型的准确度都相对接近,但 GPT-2 模型的性能最弱。这是因为对于文本分类来说,大模型更应该具有简洁且可解释的预测特征而不是生成能力。此外,随着 Tdoc 文件数量的减少,性能差距增大。
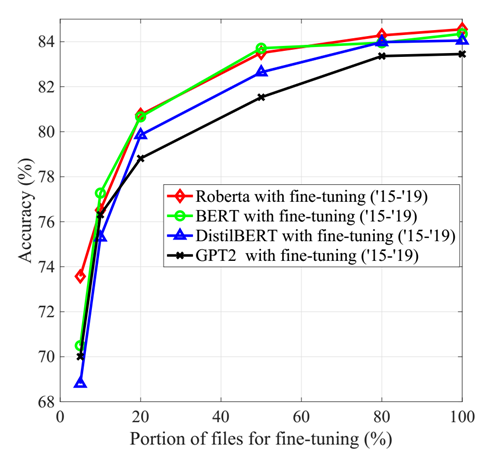
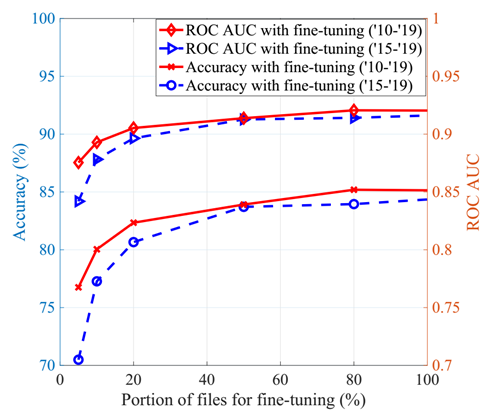
图3评估了预测的准确性和接收器操作特征-曲线下面积 (ROC-AUC),作为用于微调 BERT 模型的文本段部分的函数。可以观察到,从 2015 年到 2019 年用3GPP 文件进行微调的 BERT 模型即使只使用 20% 的文本片段,也可以实现 80% 左右的准确率性能。当文件数量相对较小(低于 10%)时,2010-2015 年的数据可以更好地理解电信技术语言。
不同3GPP工作组的作用不同,因此文件结构尤其是可用文件的数量不同。表 Ⅱ 说明了3GPP 文件的不同工作组组合对微调BERT 模型的预测结果准确性的影响。可以看出用RAN1,SA1和CT1微调的模型可以实现最好的文本片段分类精度。
表Ⅱ. 不同 WG 组合微调的BERT分类精度
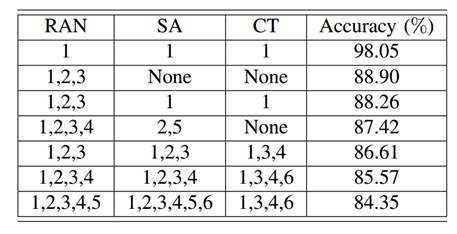
图4中,作者评估了技术文本片段的长度对分类准确性的影响。可以观察到,准确率随着单词数量的增加而增加。与此同时,性能增长的速度也在减小。因此,需要为LLM选择最佳的单词数量大小以在性能和计算复杂度之间取得平衡。
图4. 分类准确度 vs. 微调 BERT 生成的单词中的最大文本段长度
GenAINet公众号简介
GenAINet公众号由IEEE Large Generative AI Models in Telecom (GenAINet) ETI成立,由GenAINet公众号运营团队负责维护并运行。
GenAINet公众号运营团队:
孙黎,彭程晖 (华为技术有限公司)
杜清河,肖玉权,张朝阳,赫小萱 (西安交通大学)
王锦光,俸萍 (鹏城实验室)
编辑:张朝阳
校对:肖玉权