语义理解:大模型时代的embedding技术
自计算机诞生之初,科学家们就一直在探索如何让机器理解人类的语言——从最初的二进制编码系统,到复杂的自然语言处理技术。
在这一进程中,embedding技术的出现标志着一个重要的里程碑,它不仅改变了机器处理语言的方式,也为人工智能的应用开辟了新的道路。
1、二进制的世界
在计算机的世界里,无论何种数据,都必须转化为二进制形式,计算机才能进行处理。也就是任何复杂的信息都需要转换成了计算机能够理解和操作的语言——一系列的0和1。
以数字9988为例,计算机内部不直接识别这个数字,而是将其转换成二进制数10011100001000来进行存储和计算。这种转换不仅适用于数字,对于图像、文字、甚至是音频信息,计算机同样采用二进制编码来进行表示和处理。
对于图像处理来说,情况变得更为复杂和有趣。每个图像由数以百万计的像素组成,而每个像素点则通过红、绿、蓝(RGB)三个颜色通道的值来定义其颜色。这些颜色值,范围从0到255,都被转换成二进制形式。
例如,纯红色的像素可能代表为红色通道值255(二进制中为11111111),绿色和蓝色通道值均为0(二进制中均为00000000)。这种方式允许计算机精确地表示和处理图像中的每一个细节。
在处理文字和语言时,计算机同样依赖于二进制编码。每个字符,无论是字母、数字还是标点符号,都被赋予了一个唯一的二进制代码。例如,使用ASCII编码系统,字母“A”对应的二进制代码是01000001。这样文本数据就能够在计算机系统中被存储、编辑和传输。
音频数据的处理也不例外,它首先被转换为一系列的数字值,代表声音的波形。这些数字随后被编码为二进制数,使得计算机能够存储音频文件,以及对音频进行编辑和回放。
2、当计算机遇到文字
当我们的需求超越了计算机对文字的简单存储,进而希望计算机能够理解和处理语言时,就需要更先进的技术。
简单的二进制编码虽能精确表示文字,但它无法传达文字的深层含义和丰富的语境信息。这种方法忽略了语言的复杂性,包括词汇之间的关联、语言的多义性以及语境的影响。
例如,英文单词 "bank" 可以被编码为一系列二进制数字,每个字符对应一个唯一的编码。然而,这种编码方式仅仅能表示文字的表层形式,而无法捕捉到更深层次的语义和语境信息。
以"bank"为例,这个词在不同的语境下有完全不同的含义。
在金融相关的上下文中,"bank" 指的是一个金融机构;而在描述自然环境时,它可能指的是河岸。简单的二进制编码无法区分这两种情况,因为它仅仅关注于字符的直接表示,而忽略了词汇的使用上下文和含义的多样性。

此外,考虑到语言的复杂性,如同义词和反义词。简单的二进制编码处理不了"big" 和"large" 这样意义相近的同义词,也无法识别"big"和"small"这样的反义词之间的关系。
它们各自被编码为不同的二进制数,这些数无法反映出词汇之间的任何语义关联。
因此,虽然二进制编码在技术上能够准确地表示文字,但它在传达文字的深层含义、处理语言的多义性以及理解语境的影响方面存在明显限制。
这些限制使得简单的二进制编码方法在处理复杂的自然语言处理任务时显得力不从心,推动了词嵌入等更高级语义编码技术的发展,以更全面地理解和处理人类语言。
3、先来一起看电影
在介绍文字的编码之前,我们先看一个更容易理解的例子。
假设我们需要对所有的电影进行排序或编码,使得内容或风格相近的电影,在这个编码系统中距离更近或者位置相邻。

在一维数轴上排列电影
首先,我们需要确定什么因素使得两部电影被认为是相近的,例如基于电影的受众定位(儿童-成人)或者类型(如动作、喜剧、科幻)等等。
接下来,我们评估每部电影,根据确定的相似性标准对其进行分类。
最后,我们根据每部电影的分类结果,将它们进行排序或编码,使得相似的电影在这个序列中距离更近或相邻。
这些电影列表和属性如下。其中"Rating"是电影的分级评级,这个评级通常由电影分级机构根据电影的内容(如暴力、性内容、语言使用等)来确定,目的是建议电影适宜的观赏年龄或观众群体。
| Movie | Rating | Description |
|---|---|---|
| Bleu | R | A French widow grieves the loss of her husband and daughter after they perish in a car accident. |
| The Dark Knight Rises | PG-13 | Batman endeavors to save Gotham City from nuclear annihilation in this sequel to The Dark Knight, set in the DC Comics universe. |
| Harry Potter and the Sorcerer's Stone | PG | A orphaned boy discovers he is a wizard and enrolls in Hogwarts School of Witchcraft and Wizardry, where he wages his first battle against the evil Lord Voldemort. |
| The Incredibles | PG | A family of superheroes forced to live as civilians in suburbia come out of retirement to save the superhero race from Syndrome and his killer robot. |
| Shrek | PG | A lovable ogre and his donkey sidekick set off on a mission to rescue Princess Fiona, who is emprisoned in her castle by a dragon. |
| Star Wars | PG | Luke Skywalker and Han Solo team up with two androids to rescue Princess Leia and save the galaxy. |
| The Triplets of Belleville | PG-13 | When professional cycler Champion is kidnapped during the Tour de France, his grandmother and overweight dog journey overseas to rescue him, with the help of a trio of elderly jazz singers. |
| Memento | R | An amnesiac desperately seeks to solve his wife's murder by tattooing clues onto his body. |
下面是我们根据受众定位(儿童-成人)将以上电影放在一个一维的坐标轴上。可以看到《Sherk》和《Incredibles》二者相邻,因为它们都适合儿童观看。而《Memento》则是限制级R(Restricted),未满17岁需有家长陪同观看,因此远离前面提到的儿童影片。

Image Source: https://developers.google.com/machine-learning/crash-course/embeddings/motivation-from-collaborative-filtering
在二维空间中排列电影
增加到二维空间意味着我们现在可以根据两个标准来排列电影,使得相似性的表示更加丰富和精确。
我们将根据电影的受众定位(儿童-成人)和电影的类型(商业大片-艺术电影)两个维度,在二维空间中对下面一些影片进行排列,以体现它们之间的相似性和差异性。
下面是排列的结果。
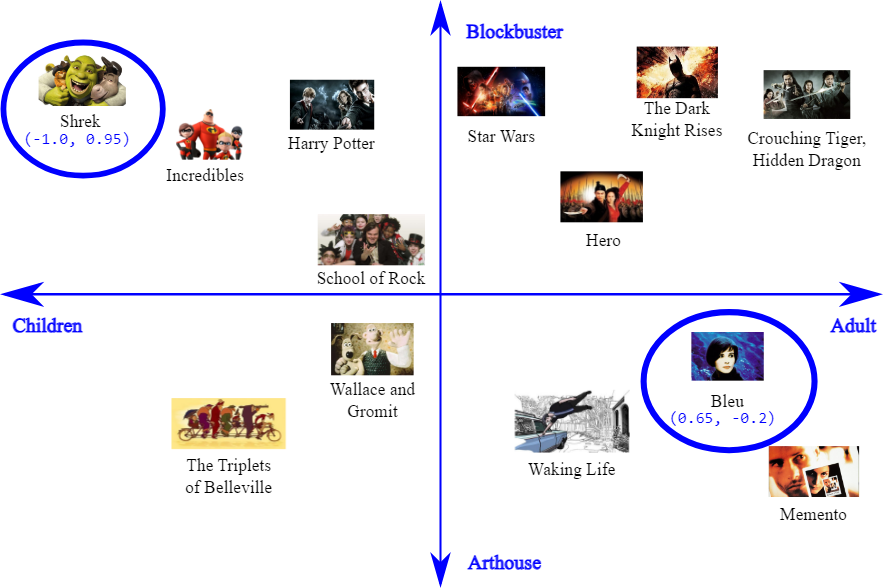
Image Source: https://developers.google.com/machine-learning/crash-course/embeddings/motivation-from-collaborative-filtering
这个图中两个维度分别是:观众类型(从儿童到成人)和电影类型(从商业大片到艺术片)。
每部电影在图中的位置由其坐标点表示,这些坐标点根据电影在这两个维度上的属性而定。例如,坐标点(-1.0, 0.95)的《Shrek》更靠近儿童和商业大片的类别,而坐标点(0.65, -0.2)的《Bleu》则更靠近成年人和艺术片的类别。
电影之间的距离或相邻程度代表了它们之间的相似性。在这个分类方法中,距离越近的电影,在观众类型和电影类型上越相似。
例如《Harry Potter》和《Star Wars》比较相近,因为他们都是商业大片,同时Rating为PG(Parental Guidance Suggested)。
Embedding space
通过这个例子中,我们可以说将电影映射到了一个embedding space中,每部电影都被赋予了一个二维坐标。
这些坐标不是随机分配的,它们体现了电影之间的某种语义相似性或者风格上的接近程度。换句话说,如果两部电影在这个空间中的坐标彼此靠近,那么我们可以推断这两部电影在某些关键维度上是相似的,无论是它们的受众定位、类型、情感调性,还是其它影响我们对电影评价的因素。
当我们进一步扩展这个概念,将电影映射到d维空间中,也就意味着我们可以对电影做多维度的评价。
在这个多维空间中,每个维度代表了一种不同的电影特征或评价标准,如剧情深度、视觉特效、导演风格、演员阵容等。
电影在这个多维空间中的位置更加全面和精细地反映了电影的整体特性和观众可能的感受。
这种方法的精妙之处在于,我们可以用一种结构化和可量化的方式来分析电影,进而发现不同电影之间的微妙关联和差异。
例如,我们可能会发现某些在表面上看起来风格迥异的电影,实际上在某个维度上有着惊人的相似性。
同样,这种多维度的电影坐标也可以用来为观众推荐电影,通过找到与他们以往喜欢的电影在多维空间中位置相近的其他电影,从而提供更加个性化和精准的观影建议。
4、呼之欲出 Embedding
这一节我们正式介绍Embedding的概念以及文本的Embedding表示的概念。
Embedding的定义
刚才我们提到了Embedding这个词,那它到底是什么含义呢?
Embeddings represent real-world objects, like words, images, or videos, in a form that computers can process. Embeddings enable similarity searches and are foundational for AI.
翻译为中文就是:
Embeddings是将现实世界中的对象,如单词、图像或视频,转化为计算机能够处理的形式。Embedding可以用于相似性搜索,也是人工智能的基石。
Embedding这个词源于"embed",意味着"嵌入"或"深入置入"某物。在自然语言处理和机器学习的语境中,"embedding"被用来描述将现实世界中的对象(如单词、图像、视频等)转换成计算机能够理解和处理的数学表示的过程。
之所以使用这个单词,是因为它形象地描绘了这一过程:将现实世界的复杂信息“深入地嵌入”到了一个可以计算和操作的数学结构(通常是向量空间)中。
在这个过程中,原始对象的核心特征和关系被提取并转化为向量形式,就好像这些特征被嵌入到了向量空间中一样。
Word Embedding
上面我们看到电影可以通过多维度的坐标来进行embedding,并表达其多方面的特征。文字——尤其是单词——也可以通过相似的思路进行表示。
在自然语言处理(NLP)领域,单词嵌入(word embedding)将单词转换为n维向量空间中的点。
这个向量不是随机生成的,而是经过悉心计算,使得每个维度能够捕捉到单词的某种语义或语法属性,从而使得语义或语法上相似的单词在这个向量空间中彼此相依。
一个好的嵌入能够更准确地反映单词之间的关系,比如同义词、反义词、上下位关系等,因此Embedding方法至关重要,高质量的embedding可以极大地提高自然语言处理任务的性能,如文本分类、情感分析、机器翻译等。
维度在embedding中同样重要。太少的维度可能无法充分捕捉到单词的所有语义特征,导致不同单词之间的区分度不够;而太多的维度则可能引入过多的噪声,使得模型训练变得更加困难,且效率降低。因此,选择合适的维度是实现embedding的关键。
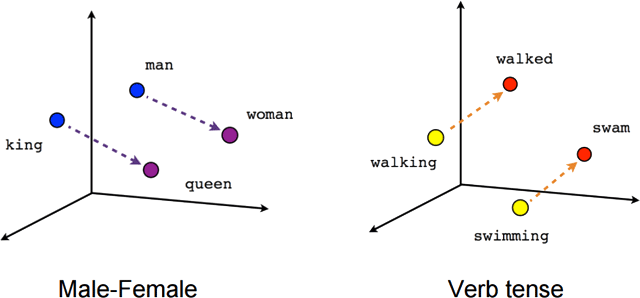
我们来看几个单词的示例:man, woman, king, queen。
以这四个单词为例,假设我们使用某种embedding方法将它们映射到一个二维空间中,我们会发现:
“man”和“woman ”在嵌入空间中的位置彼此接近,因为它们都表示人类,只是在性别属性上有所区分。 类似地,“king”和“queen” 也会彼此接近,因为它们都与王室有关,同样在性别上有所区分。 进一步地,我们可能会发现“man” 和“king” 之间、以及“woman” 和“queen” 之间的距离较近,因为它们在性别和社会角色上分别相似。
我们还可以用数学方法来量化和分析单词之间的关系。例如,通过向量运算,我们可以发现“king” - “man” + “woman” 的结果与“queen”的向量非常接近,这种现象揭示了embedding空间中性别和社会角色维度的有趣关系。
那单词的embedding又是从何而来呢?
Image source: https://openai.com/blog/new-embedding-models-and-api-updates
5、WORD2VEC
Word2vec是一种非常重要的word embedding方法,由Google Tomas Mikolov等于2013年提出。主要目标是将单词转换为向量形式,这些向量能够捕捉到单词之间的语义关系和语境信息。
Word2Vec使用一个浅层的神经网络架构来学习单词的向量表示,尽管它的结构相对简单,但其能力却非常强大。这个网络不是为了完成传统意义上的任务,如分类或回归,而是用来学习单词的密集向量表示,这些表示能够捕捉到丰富的语义信息和语言结构。
Word2vec的思想
Word2vec的核心思想基于假设:“一个词的含义可以通过它周围的词来定义”,即“词的上下文”。
基于这个假设,Word2vec利用神经网络模型从大量文本数据中学习单词的向量表示,使得在语义上相近的单词在向量空间中也相互靠近。
Word2vec模型主要有两种架构:Continuous Bag-of-Words(CBOW)和Skip-Gram。
CBOW模型通过上下文(即周围的单词)来预测当前单词,而Skip-Gram模型则正好相反,它使用当前单词来预测其上下文。这两种方法都能有效地捕捉到单词之间复杂的语义关系和模式。
例如对于句子“猫坐在垫子上”。
在CBOW模型中,如果我们选择“坐在”作为目标词,那么上下文词可能是“猫”和“垫子”。CBOW模型的任务是根据上下文词“猫”和“垫子”来预测目标词“坐在”。模型通过查看这些上下文词来学习“坐在”的表示方式,从而能够在遇到类似上下文时预测出正确的目标词。
使用同样的句子“猫坐在垫子上”。在Skip-gram模型中,如果我们选择“坐在”作为输入词,那么模型的任务是预测它周围的上下文词,即“猫”和“垫子”。与CBOW相反,Skip-gram模型通过观察单个目标词来学习预测其上下文环境,从而能够根据给定的单词推测出它可能出现的上下文词。
可以看出CBOW和Skip-gram模型都是通过学习词语的上下文来捕捉词义的,但它们的学习方式正好相反。CBOW模型以上下文词为输入,预测目标词,适合快速学习词汇的总体语义;而Skip-gram模型则以目标词为输入,预测上下文词,更擅长捕捉特定词汇的细微语义差异,特别是对于罕见词汇或特定语境下的词汇。
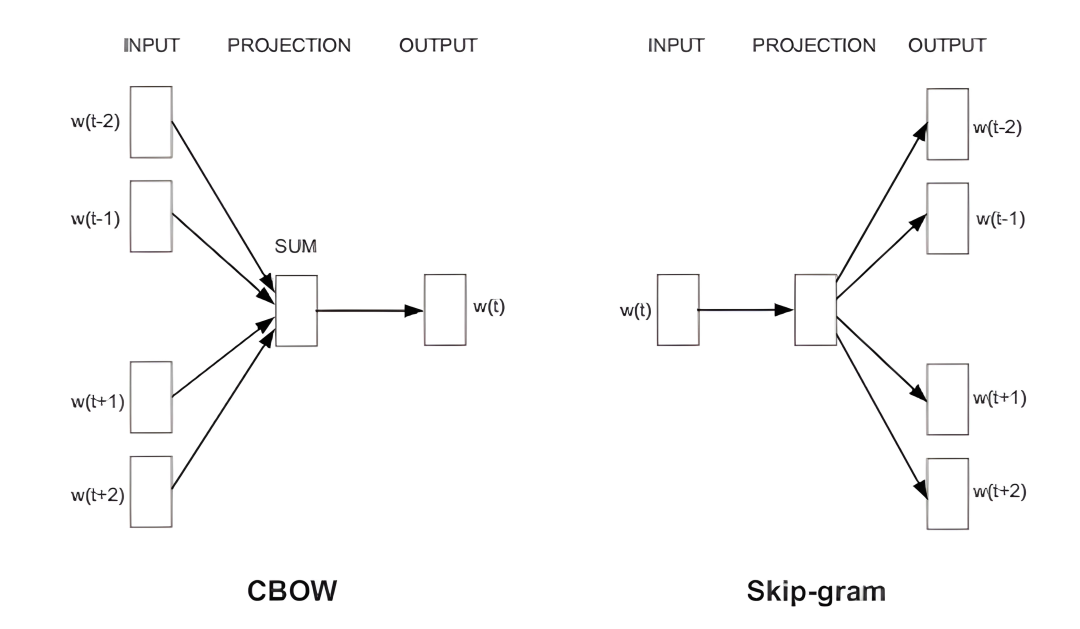
Image source: https://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
Skip-gram模型架构示例
需要注意的是,上面的预测任务(比如用CBOW模型预测目标词,或者用Skip-gram模型预测上下文词)本身并不是我们的最终目标。
这些预测任务更像是一种代理过程,其真正的目的是通过这个过程学习到词语的向量表示。
我们通过一个Skip-gram模型的例子来解释上面的话。
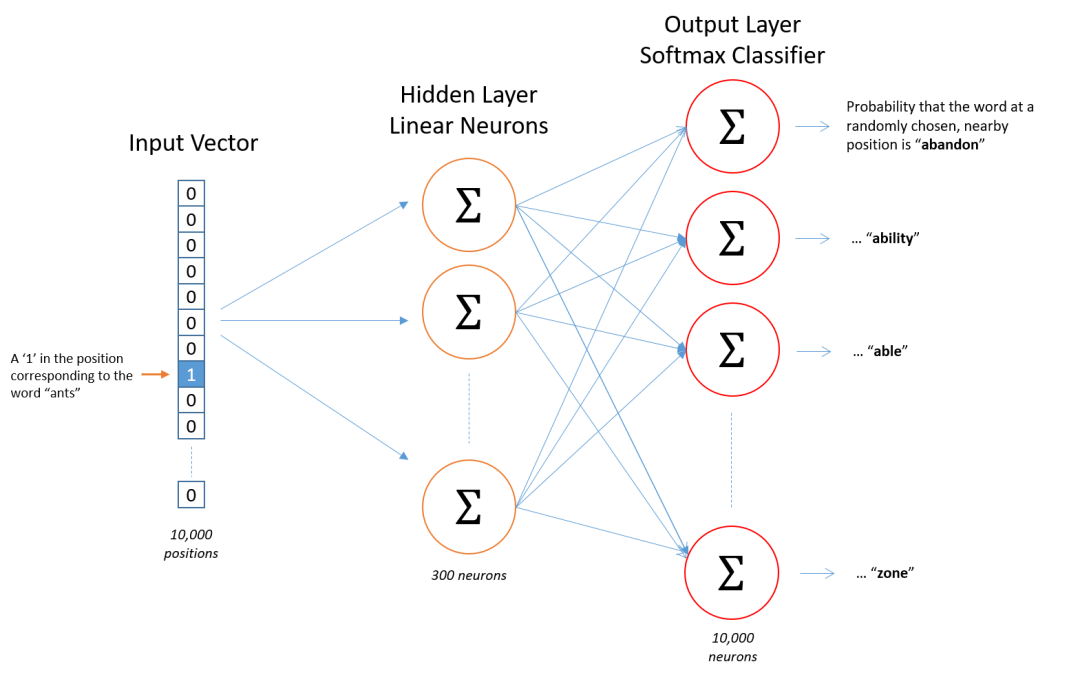
Image source: https://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
在Skip-gram模型中,网络的结构设计是为了从一个给定的目标单词预测上下文中的单词。以一个词汇量为10,000个单词的语料库为例,我们来探讨Skip-gram网络结构的细节。
在神经网络中,网络由多个层次的节点(或称为"神经元")组成,这些层次依次连接构成了网络的结构。在最简单的形式中,神经网络包括输入层、隐藏层和输出层。每一层都由多个节点组成,而每个节点则是计算的基本单元。输入层接收原始数据,输出层提供最终的计算结果,而隐藏层则位于输入层和输出层之间,负责进行实际的计算和数据的中间表示。
模型输入
模型的输入是一个单词,表示为10,000维的one-hot向量。在one-hot编码中,每个单词都由一个具有10,000个元素的向量表示,其中一个元素设为1(表示当前单词),其余元素都设为0。
例如假设句子为:The quick brown fox jumps over the lazy dog。
如果我们的输入单词是“brown”,则“brown”在词汇表中的对应位置将被标记为1,而其他位置为0。
网络隐藏层
网络的隐藏层通常较小,假设有300个神经元。这意味着输入的10,000维one-hot向量会被映射到一个300维的隐藏层。
这个隐藏层可以被视为一个特征提取层,它从输入单词中提取出300个特征。
这些特征并不是预先定义的,而是通过训练数据自动学习得到的。它们能够捕捉到与单词相关的重要语义和上下文信息。
提到这些特征“是通过训练数据自动学习得到的”,我们是指模型不需要人工输入或指定应该学习什么特征。相反,模型通过观察输入数据和对应的输出(或目标),自动调整其内部参数(权重和偏差)。
例如,在Word2Vec模型的训练过程中,模型通过大量的文本数据学习。初始时,模型内部的权重是随机初始化的,这意味着模型对于数据中的任何特征都是“无知”的。然而,通过不断地处理输入数据(单词或单词序列),并尝试预测其上下文(Skip-gram模型)或根据上下文预测目标单词(CBOW模型),模型内部的权重会逐渐调整。
这种权重调整过程是通过优化算法(通常是梯度下降或其变体)实现的,旨在减少模型的预测误差。随着模型在大量文本数据上的反复训练,它逐渐学习到如何通过这些权重捕捉单词之间的语义和语法关系,这也是神经网络的神奇之处。模型不需要显式编程来识别这些复杂的单词关系,而是自动从数据中学习到了如何表示这些关系。
随着训练的进行,模型逐渐学会了哪些内部表示(特征)能够有效地捕捉单词之间的关系,比如语义相似性、语法结构等。
模型输出
输出层是一个10,000维的向量,其中的每个元素代表词汇表中每个单词作为当前输入单词的上下文单词的概率。回到我们的例子,“The quick brown fox jumps over the lazy dog”,如果输入是“brown”,那么理想的输出向量会在“quick”、“fox”、“jumps”等上下文单词的位置上有较高的概率值。
整个网络的大小主要由两部分决定:从输入层到隐藏层的权重,以及从隐藏层到输出层的权重。对于一个词汇量为10,000,隐藏层为300的模型,从输入层到隐藏层的权重矩阵大小为10,000 x 300,从隐藏层到输出层的权重矩阵大小为300 x 10,000。因此,整个模型大约有3,000,000(输入到隐藏层)+ 3,000,000(隐藏层到输出层)= 6,000,000个权重需要在训练过程中学习。
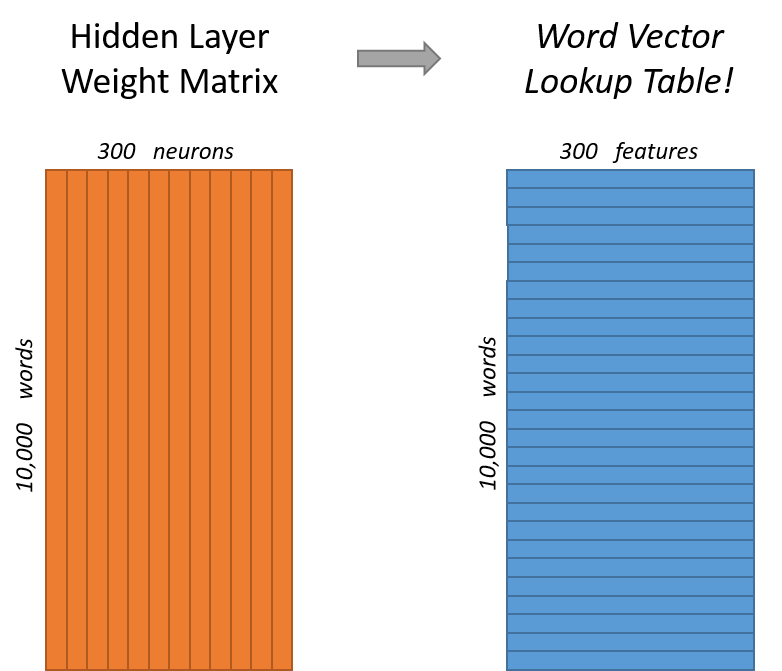
Image source: https://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
单词的向量在哪里
在使用Word2Vec模型训练完毕后,词向量就储存在模型的权重中。例如我们将输入中某个维度设为1(输入为某个单词),则与矩阵运算后,得到的就是这个单词的词向量。

Image source: https://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
通过这个网络结构,Skip-gram模型能够学习到每个单词的向量表示,这些向量包含了单词的丰富语义和上下文信息。这些向量(即隐藏层的权重)就是我们所说的word2vec embedding,它们可以被用于各种自然语言处理任务。
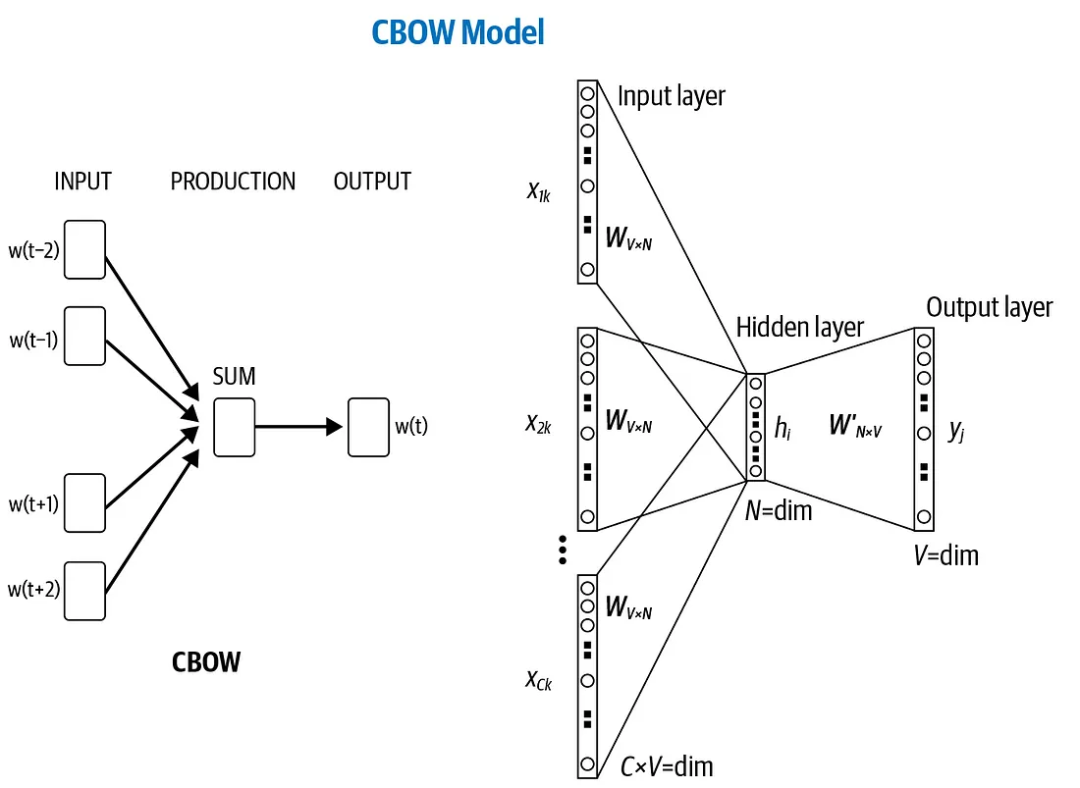
CBOW模型架构示例
对于CBOW模型的输入,每个上下文单词首先被表示为one-hot向量。假设词汇表大小为10,000个单词,且上下文窗口大小为C(例如,如果C=2,则表示每个目标词的左右各有2个上下文词),那么输入层将会接收C个10,000维的one-hot向量。
然后,模型利用这些one-hot向量来从预先初始化的embedding矩阵中查找相应的embedding向量。embedding矩阵的每一行代表词汇表中一个单词的向量表示。这些embedding向量是模型要学习的目标,它们捕获了单词的语义信息。
在CBOW中,一旦得到上下文中每个单词的embedding向量后,模型并不是对这些向量进行复杂的变换,而是采取更简单的方法:将这些向量直接相加或求平均。这个过程生成了一个单一的固定大小的向量,代表了给定上下文的整体语义。这个向量随后被用作预测中心词的基础。
举例说明:
假设我们的上下文词是“the”, “cat”, “on”, “the”, “mat”,我们的目标是预测“sat”的embedding向量。
在CBOW模型中,我们首先找到“the”, “cat”, “on”, “the”, “mat”在embedding矩阵中对应的embedding向量。假设每个向量都是300维的,我们将这五个向量相加或求平均,得到一个代表整个短语“the cat on the mat”的300维向量。
这个向量捕获了短语的整体语义,而忽略了单词间的顺序和细微差别,然后用来预测目标词“sat”的概率分布。
通过这种方法,CBOW模型可以有效地利用上下文信息来预测中心词,同时通过反向传播算法在训练过程中更新嵌入向量,使其能够捕捉更丰富的语义关系。这种直接使用嵌入向量的加和或平均的策略,简化了计算过程,同时保留了足够的信息用于后续的预测任务。
6、Embedding 大模型
Word2Vec提供了一种高效的方式来学习单词嵌入,捕获词语间的语义关系,但随着自然语言处理(NLP)领域的发展,对于更复杂、更准确的语义表示的需求日益增长。
这促使了基于大型语言模型(如GPT)的embedding方法的发展。这些基于大模型的embedding相比Word2Vec具有几个关键优势:
更丰富的上下文理解大型语言模型能够捕捉更长的上下文信息,这使得它们在理解单词在特定语境中的含义方面更为准确。Word2Vec通过固定大小的窗口来考虑上下文,而大型语言模型可以考虑整个句子或超过句子界限的上下文,提供更深层次的语义理解。
动态词嵌入Word2Vec为每个单词生成一个固定的embedding向量,不考虑单词的上下文使用情况。相反,基于大型语言模型的embedding是动态的,即同一个单词在不同上下文中可以有不同的embedding表示。这对于理解多义词和捕捉复杂的语言现象特别重要。
深层次的语言特征学习大型预训练语言模型如GPT在训练时使用了海量的文本数据,能够学习到更深层次的语言特征和模式。这些模型通常包含数十亿个参数,能够捕捉到语言中微妙的规律和复杂的结构,为各种NLP任务提供更强大的特征表示。
更广泛的应用适用性基于大型语言模型的embedding不仅适用于传统的NLP任务,如文本分类或情感分析,还能用于更复杂的任务,如问答系统、文本生成和机器翻译等。
因此基于大型语言模型的嵌入方法通过提供更丰富的语义表示、更准确的上下文理解和更强大的特征学习能力。
下面我们介绍OpenAI的几个embedding模型:
text-embedding-3-large
描述:这是一个新的大型嵌入模型(Embedding V3 large),被认为是目前最强大的嵌入模型之一,适用于英语和非英语任务,在多语言处理方面具有较好的通用性和性能。 输出维度:3,072。即每个文本embedding的向量大小。较大的维度通常意味着模型能够捕捉更多的信息和细节,但同时也需要更多的计算资源来处理这些向量。
text-embedding-3-small
描述:这是Embedding V3系列的小型版本(Embedding V3 small),与前一代ada嵌入模型相比,性能更高。
输出维度:1,536。较小的输出维度使得这个模型在处理速度和资源使用方面更为高效,同时仍然保持了较好的性能。
text-embedding-ada-002
描述:这是最强大的第二代嵌入模型,取代了16个第一代模型。
输出维度:1,536。
| Model | Description | Output Dimension |
|---|---|---|
| text-embedding-3-large | New Embedding V3 largeMost capable embedding model for both english and non-english tasks | 3,072 |
| text-embedding-3-small | New Embedding V3 smallIncreased performance over 2nd generation ada embedding model | 1,536 |
| text-embedding-ada-002 | Most capable 2nd generation embedding model, replacing 16 first generation models | 1,536 |
在文本嵌入模型中,维度数(例如,3,072维)反映了模型生成的向量的大小或复杂性。每个维度可以被视为捕捉文本中某种语言特征或语义信息的一个方面。
较高的维度数意味着模型能够捕捉更多的信息和更细微的语义差别,从而在理解文本、区分语义细节方面表现得更好。然而,这也意味着模型需要更多的计算资源来处理这些高维度的向量。
Word2Vec等传统词嵌入模型主要关注于单词级别的embedding,生成的是单个单词的向量表示。然而,许多现代嵌入模型,尤其是基于大型语言模型的embedding(如GPT系列),能够处理更长的文本片段,生成的嵌入表示能够捕捉到整个文本片段或句子的综合语义信息。这种类型的embedding通常更适用于理解文本的整体意义、处理复杂的语义关系和文本生成等任务。
7、Embedding用来做什么?
在大模型时代,Embedding技术已经成为自然语言处理(NLP)任务的核心工具之一。
Embedding技术能够将文本数据转换为机器能够理解的数值型向量,这些向量捕捉了单词、短语或整个文本段落的语义信息。这些向量表示形式被广泛应用于各种NLP任务中。
我们在这里列举几个应用的场景。
语义相似度计算
语义相似度计算旨在评估两段文本在意义上的相似程度。这个过程涉及到理解和比较文本中所表达的概念、意图和情感等多个层面的内容。
在大模型时代,文本的语义相似度计算可以通过以下步骤完成:
文本嵌入:首先,使用预训练的语言模型(如Word2Vec、GloVe、BERT、GPT等)将文本转换成高维空间中的向量。将文本的语义信息编码到向量中,使语义上相似的文本被映射到向量空间中的相近位置。
向量比较:一旦文本被转换为向量,接下来就是比较这些向量的相似度。这可以通过多种方式实现,如计算向量之间的余弦相似度、欧几里得距离、曼哈顿距离等。余弦相似度是最常用的一种方法,它测量两个向量在方向上的接近程度,可以有效地捕捉文本的语义相似性。
文本搜索
随着数据量的快速增长,我们需要从大规模文档集合中快速准确地找到相关文档。
基于embedding的文本搜索模型通过为文档和查询生成embedding向量,然后使用向量之间的相似度(如余弦相似度)来寻找匹配的文档。
这种方法能够捕捉文本的语义含义,而不仅仅依赖于字面的词汇重叠,因此在处理同义词和上下文相关的查询时更加有效。
下面是一些实际的应用场景:
文档检索:在法律、学术和企业领域,用户经常需要从大量文档中检索出相关的资料。基于嵌入的搜索可以根据查询的语义意图,快速返回最相关的文档。 常见问题解答(FAQ)检索:对于客户支持系统,基于嵌入的搜索可以帮助快速找到与用户查询语义相匹配的常见问题解答,即使用户的提问方式与FAQ中的措辞不完全一致。 论坛和社交媒体内容探索:在论坛或社交媒体平台上,用户可能希望根据特定的主题或兴趣点来探索内容。基于嵌入的搜索能够理解查询的语义,提供更加相关的内容推荐。
OpenAI 曾给出一个案例,JetBrains Research的天体粒子物理实验室负责分析专业的数据报告。这些报告包含了天文事件的信息,由于其专业性和复杂性,传统的算法难以解析这些报告中的内容。
借助OpenAI的embedding技术,研究人员现在能够在多个数据库和出版物中搜索特定的天文事件,例如“蟹状脉冲星爆发”(crab pulsar bursts)。这种搜索方法不仅仅基于关键词的重叠来寻找相关的文档,而是利用嵌入向量捕捉文本的语义含义,从而能够更准确地找到描述相似事件的报告,即使这些报告中没有使用完全相同的短语或关键词。
推荐系统
推荐系统可以并且已经在广泛地使用embedding技术。在推荐系统中,embedding技术被用来将用户和物品(比如电影、书籍、商品等)转换为向量形式的低维表示。这种向量表示捕捉了用户的偏好和物品的特性,使得推荐系统能够通过计算向量之间的相似度来预测用户对未知物品的偏好。
推荐系统中使用embedding的步骤:
用户和物品embedding:通过训练过程,为每个用户和物品生成embedding向量。用户embedding向量试图捕捉用户的偏好,而物品embedding向量则表示物品的特性。这些embedding通常是通过用户与物品的交互数据(如评分、浏览、购买历史)学习得到的。
计算相似度:一旦获得了用户和物品的嵌入,推荐系统可以通过计算用户embedding向量和所有物品embedding向量之间的相似度来识别最可能吸引用户的物品。常用的相似度度量方法包括余弦相似度和点积。
生成推荐:根据相似度的计算结果,系统可以为每个用户推荐一组最有可能感兴趣的物品。这些推荐可以是基于用户过去行为的延伸,也可以是探索新领域,取决于推荐算法的设计。
相比于传统的基于规则或简单统计的方法,embedding技术能够更好地捕捉用户和物品的深层次特征和复杂的关系。
RAG(Retrieval-Augmented Generation)
RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的机器学习方法,特别用于处理需要广泛知识支持的自然语言处理任务。
这种方法首先从一个大型的文本数据库中检索出与给定查询最相关的文档片段,然后基于这些检索到的文档,生成回答或内容。RAG模型通过将检索和生成结合起来,能够在回答问题、写作、对话系统等任务中利用到比单一模型更丰富的信息源。
以问答系统为例,假设用户提出了一个关于“黑洞”的问题。RAG模型首先从其连接的文档数据库中检索与“黑洞”相关的文档片段,然后基于这些文档内容生成一个准确、信息丰富的答案。这种方法相比传统的基于规则或仅基于生成的模型,能够提供更为精确和信息丰富的回答。
RAG通过结合检索和生成的能力,大大扩展了生成式大语言模型处理复杂自然语言任务的能力。
Image source: https://aws.amazon.com/what-is/retrieval-augmented-generation/
通过将文本转换为嵌入向量,大模型使得上述任务的处理变得更加高效和精准。这些应用场景仅仅是嵌入技术在NLP领域广泛用途的一部分,随着技术的进步,Embedding模型将在更多领域展现其潜力。
8、结语
Embedding技术使得机器能够理解和处理自然语言,通过将单词、短语乃至整段文本转换为数值型的向量表示,它们为机器提供了一种理解语言的方式。
这种转换不仅捕捉到了语言的表层特征,还能够揭示深层的语义关系,为各种语言相关任务提供支持,包括文本分类、情感分析、机器翻译、问答系统等。
因此,可以说,embedding技术是连接人类语言与机器智能的桥梁,是推动人工智能发展的核心力量之一。