最近负责的项目组事儿好多,写文章的时间也少了好多~~~

1.前言
话不多说,进入正题!今天分享的是一种称之为“文本顺滑”的算法,文本顺滑即是用来识别出口语中自带的不流畅文本。随着ASR/自动语音识别的流行,NLP相关系统获取到的用户口语文本往往含有大量的不流畅表述。这些不流畅表述的来源有两点:(1)ASR系统识别错误导致;(2)用户话中自带的。然而目前NLP的相关系统底层训练数据都是比较流畅的文本,这些具备不流畅表述的文本对于NLP的相关任务会造成严重的干扰,不利于模型的鲁棒性以及准确率提升。
2.理论介绍
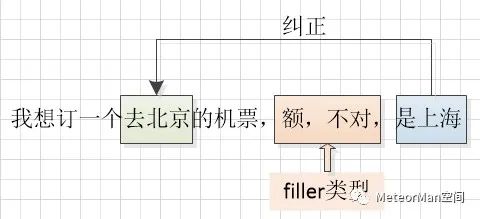
文本顺滑算法主要解决两类任务:Edit类型和Filler类型。Filler类型主要包括“uh”、“oh”、“emm”以及“额~”、“我想想”等标记语。Filler类型所对应的不流畅表述大多为常见的短语集合,利用简单的规则和机器学习模型就可以很好的识别出来。然而Edit类型较为复杂,它主要包括重复以及被后面的短语所纠正的部分。如下图所示,“额”、“不对”属于Filler类型,“去北京”则属于Edit类型,其被后面的“是上海”所纠正。由于Edit类型的短语长度不固定,出现的位置比较灵活,有时还会出现嵌套的结构,因此文本顺滑算法的研究主要集中在Edit类型的处理上。
针对文本顺滑算法,存在两个研究难点:长距离依赖和句法完整性。
• 长距离依赖:一方面表现在Edit类型与其文本中对应的修正部分中间可能间隔着许多词语;另一方面表现在Edit类型的短语集合本身长度会很长;基于这两个方面要让模型去判断一个词是不是Edit类型,就需要看到距离这个词语较远距离的信息。• 句法完整性:文本顺滑算法的关键是要保证顺滑过后的句子的句法完整性,如果句中的一个关键成分被误认为Edit类型,将会导致严重后果。3.现有方法介绍
对于文本顺滑,现有的工业界解决方案少得可怜,大多集中在学术研究方面。目前的研究方案大致可以分为四类:序列标注方法、句法和顺滑联合方法、基于RNN的方法以及基于seq2seq的方法。所采用的数据集大多是English Switchboard。
3.1 序列标注方法
使用序列标注机制来解决文本顺滑的算法可以分类为两类:
(1)基于词的序列标注方法
这类方法很简单,就是直接利用序列标注模型的原理给句中每个词赋予一个标签(Filler的BIEO和Edit的BIEO体系),最后根据标签来判定每个词语的类型(Filler/Edit)。
(2)基于块的序列标注方法
这类基于块(chunk)的方法不再是对每一个词语单独附一个标签,而是对每一个块的短语集合单独附一个标签,其输出也就不再是与输入等长的标签序列,而是一个个带标签的短语集合块。
传统的序列标注模型通过设计复杂的离散特征,可以在一定程度上解决长距离依赖问题,但是受限于训练语料的规模,往往会面临稀疏性的问题。而且,这类方法没有能力保证生成句子的句法合理性。
3.2 句法和顺滑联合方法
Switchboard数据集在标注顺滑语料的同时也标注了相应的句法成分,针对这一点,一些研究工作将句法分析和顺滑任务联系在一起,具体做法一般是首先利用固定方式将句法成分转换成句法分析的依存句法树,随后通过通过某些方法将顺滑任务融入到句法分析的过程中,以此达到二者联合处理的目的。 这种方法可以将顺滑相关的特征与句法结构特征融合,进一步促进长距离依赖问题的解决;然而仍然存在两个问题:• 一个是速度慢。这种联合的方法需要同时做句法依存分析和顺滑任务,相对于3.1的序列标注方法,速度会慢很多。• 另一个是语料标注代价高。要想实现这种联合分析的方法,训练测试所需的语料需要同时包含句法成分标注和顺滑成分标注,这种标注的代价是很高的,进一步降低了这种方法的实用性。3.3 基于RNN的方法
既然上文提到了长距离依赖问题,那么就不可避免的会联想到RNN的解决方案。RNN理论上就是为了解决长距离依赖问题而提出的。自然会有研究者使用RNN来解决顺滑任务,之前有人引入双向LSTM来针对每个位置的词进行分类进而判断其是否为Edit类型,实验效果也超过了之前介绍的序列标注方法和顺滑联合方法。但是这种直接引入LSTM进行分类的方法忽略了一点:未考虑标签之间的联系,会导致label bias问题。前面提到过顺滑任务中一个不流畅表述可能会包含多个词语,这会导致其输出标签之间会存在很强的依赖性。为了解决这个问题,在LSTM的基础上又引入了CRF,首先通过双向LSTM学习每个位置词语的隐层特征,随后将特征输入到线性CRF层,实验效果较单纯的LSTM有所提升。 这类方法虽然后续也融入了一些重要的人工特征来促进模型性能的提升,可以更好的解决长距离依赖问题,但是对于句子的句法完整性却忽略了。3.4 基于Seq2Seq的方法
随后研究者利用Seq2Seq机制来解决顺滑任务,主要考虑到两点:(1)seq2seq机制的编码器会对句子进行全局建模,有利于顺滑任务中长距离依赖问题的解决;(2)seq2seq机制可以看做是基于条件的语言模型,原始的输入句子就是这个语言模型的条件成分,解码器阶段就是这个语言模型的生成过程,从这个角度看有利于顺滑任务生成句子的句法完整性问题的解决。但是顺滑任务要求删除不流畅部分后的句子必须是原始输入句子的有序子序列,这意味着生成的句子既不能额外增加一些原始输入句子中不存在的词,也不能改变词的顺序,传统的se2seq框架显然不能满足顺滑任务的要求,主要表现在:• 一是其每步生成新词的时候,都会在一个固定的词表中去选择一个概率最大的词,这样就可能会生成一个不在原始句子中出现的词;• 二是其只能在固定的词表中去选词,如果原始句子中出现了一个不在词表中的词,那么这个词就肯定不会被生成; 为了可以让seq2seq机制适用于顺滑任务,pointer network应运而生,但是仍然没有能力保证生成词的有序性。因此如下图的结构被提出来,通过修改pointer network的解码过程来保证生成词的有序性,进而将该机制应用到顺滑任务中。在编码阶段,用一个双向LSTM对句子进行编码,然后将得到的句子表示作为解码阶段单向LSTM的初始隐层输入。在解码阶段,每一步模型都会对输入句子的选定窗口内的词进行attention操作,然后将权重最大的词作为要生成的词,一旦一个词被选中,那么,窗口内位于该词前面的那些词都默认被删除掉,也就是被标注为不流畅词。下一步的窗口将从当前被选中的词的下一个位置的词开始,窗口的长度由训练语料中不流畅块的最大长度和输入句子中剩下的词的个数来决定。图中的白色箭头代表的就是被选中的权重最大的词。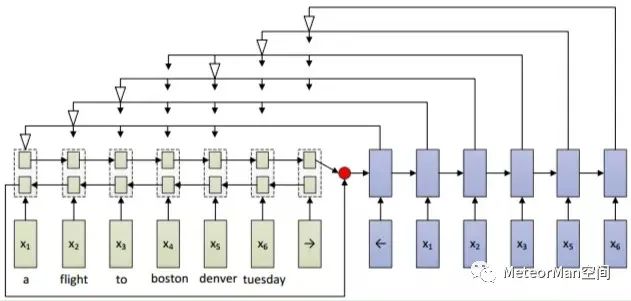
实验结果表明,该模型的性能和LSTM-CRF模型的性能接近。从模型本身来看,encode-decode框架能很好的解决长距离依赖问题,还有一定的能力保证生成句子的句法完整性,但是由于模型在训练和测试阶段都采用的是贪心搜索策略,一旦中间步骤选错了词,会对后面的步骤产生严重的影响。4.前沿方法介绍
目前大部分在文本顺滑任务上的工作都严重依赖人工标注数据,为了减少对有标注数据的依赖,AAAI2020的一项工作Multi-Task Self-Supervised Learning for Disfluency Detection尝试用自监督学习的方法来处理文本顺滑任务。自监督学习可以看作是一种特殊的有监督学习,跟传统有监督学习方法的主要区别是其用到的标签不是通过人工标注的,而是通过一定的方式自动产生的。例如将一张图片切分成若干个子块,然后将随机打乱顺序的子块作为输入,正确的排列顺序就可以作为有监督的标签。 论文提出的方法如下图所示,主要是利用现在流行的预训练+微调两步策略进行,主要包括三个部分:• 2.基于构造的伪数据对两个自监督任务进行预训练;• 3.基于预训练的结果在人工标注的文本顺滑数据集上进行微调。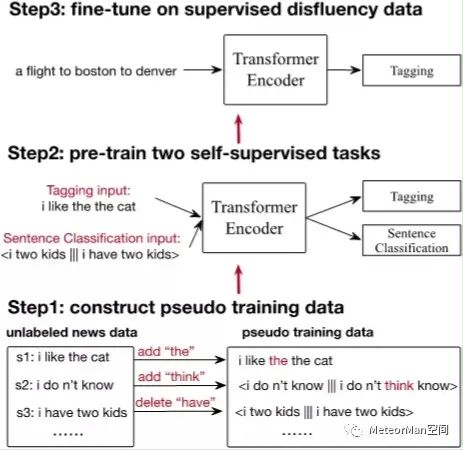
论文中指出,使用BERT针对文本顺滑数据进行微调后,与论文工作的实验性能对比如下图所示: 使用全部人工标注数据进行微调时,论文工作得到了与BERT相似的结果。特别是当只用1%(1000句)左右人工标注数据进行微调时,论文方法比BERT要高3.7个点左右。最后,论文尝试将模型和BERT模型结合起来,具体做法是在微调时,将论文模型和BERT模型的隐层输出结合起来做序列标注任务,实验结果证明模型结合之后能取得更高的性能,这也证明了论文模型学习到了BERT之外的对顺滑任务有帮助的信息。5.总结
本文首先将基于数据驱动的模型划分为4种类型,随后为了降低这些方法对于人工标注数据的依赖,引出自监督学习工作,其实验结果也证明该方法只利用1%左右的有标注数据就能实现与之前最好方法类似的性能,大大减轻了对有标注数据的依赖。 但是目前的方法仍然知识集中在解决一些简单的不流畅现象,如简单的重复等。但是对于比较复杂的问题,如语义层面的重复,修正等,现有的基于数据驱动的模型还不能很好地解决,未来还有很大的探索空间。