开源:基于AI大模型的语义通信
题目:Large AI Model-Based Semantic Communications
作者:Feibo Jiang, Yubo Peng, Li Dong, Kezhi Wang, Kun Yang, Cunhua Pan,Xiaohu You
内容整理:江沸菠,彭于波
期刊:IEEE Wireless Communications Magzine
代码:https://github.com/jiangfeibo/LAMSC.git
论文地址:https://arxiv.org/abs/2307.03492(查看全文请点击原文链接)
摘要:语义通信(SC)是一种新兴的智能范式,为未来的各种应用(如元宇宙、混合现实和万物互联)提供解决了方案。然而,在当前的语义通信系统中,知识库(KB)的构建面临着一系列挑战,包括有限的知识表达、频繁的知识更新和不安全的知识共享。幸运的是,AI大模型包含了广泛的世界知识,能够为语义通信的知识库构建提供强大的支持。本文提出了一种基于AI大模型的语义通信(LAM-SC)框架。首先设计了基于Segment Anything Model(SAM)的知识库(SKB),它可以利用通用的语义知识将原始图像分割为不同的语义片段。然后,提出了一种基于注意力的语义整合(ASI),以权衡由SKB生成的语义片段,并将它们集成为具有语义感知的图像。此外,提出了一种自适应语义压缩(ASC)编码,以消除语义特征中的冗余信息,减少通信开销。最后,通过模拟实验,证明了LAM-SC框架的有效性以及基于大AI模型的知识库在未来语义通信中的重要性。
目录
1. 引言
1.1 语义通信系统中通用知识库的组成
1.2 语义通信系统中当前知识库方案存在的问题
1.3 贡献
2. 语义通信系统中基于AI大模型的知识库
2.1 基于AI大模型知识库的优势
2.2 语义通信系统中AI大模型的设计建议
3. LAM-SC框架的架构
3.1 LAM-SC框架简介
3.2 SKB
3.3 ASI
3.4 ASC
4. LAM-SC框架的训练
5. 仿真结果
6. 开放性问题
7. 结论
1. 引言
1.1 语义通信系统中通用知识库的组成
KB对于SC系统来说至关重要,因为它能够理解和推断语义信息,从而使SC系统与传统通信系统区别开来。通过学习大量的世界知识,可以构建一个通用KB,这构成了SC系统的核心。通用KB包括用户能够理解和识别的先验知识以及背景知识。
2)背景知识:语义信息不仅仅是显性信息,还涉及上下文、隐含意义和常见事实。例如,在图2中,显性信息是家猫和老鼠,隐性的背景知识是动画片《猫和老鼠》。同样,语义通信也涉及发送方和接收方之间的背景知识交流,如用户身份、兴趣偏好和用户环境等,这些有助于语义编码器提取双方都感兴趣的最相关的信息和语义解码器进行准确的信息恢复。因此,背景知识也是语义通信中的一个关键因素,用于辅助语义通信系统实现准确的语义推断,消除冗余,并确保发送方和接收方之间对于信息认知的一致性。
1.2 语义通信系统中当前知识库方案存在的问题
1)有限的知识表示:使用传统的深度神经网络或知识图谱作为知识库时,知识库的网络层数与参数上限通常较低,并且需要通过监督学习进行持续学习,其中对收集的数据进行标注也会带来高昂的人工成本。这些缺点使得该知识库难以拥有丰富的语义知识和捕捉人类知识中潜在含义的能力,即语义提取能力。例如,“苹果公司”和“苹果汽水”中的“苹果”在传统的词嵌入模型中会被错误的表示为相同的特征。
2)频繁的知识更新:基于传统深度学习模型的知识库需要在环境中的知识领域发生变化时,通过重新训练和共享不断更新知识。然而在现实世界中,数据的流通是频繁的,因此必须高频率的更新知识库以保证其正常运行,这会导致巨大的资源开销。例如,一个面向翻译任务的知识库需要包含特定的语言知识,当对话涉及到新的语言时必须及时更新相应的知识才能完成任务。
3)不安全的知识共享:因为感知环境的差异,通信双方拥有的知识往往是不同的,所以对于同一信息双方可能会有不同的语义理解,这就导致了语义上的偏差。因此,共享的知识库需要确保通信双方对于传输信息在语义层面认知的一致性,这就要求不同用户之间需要频繁同步知识库。然而,由于这些知识库中可能包含一些高度敏感的与用户隐私相关的信息,频繁的更新会引入潜在的隐私和安全风险。例如,面向医疗领域的知识库中可能包含患者身份、病史等信息,因此同步的过程中存在泄露敏感信息的可能。
1.3 贡献
最近,AI大模型有了重大进展,AI大模型是指一种具有数百千亿参数的高级Transformer模型。随着计算能力的不断提高和数据量的增加,AI大模型近年来在自然语言处理、图像识别和语音识别等领域取得了重大进展。它具有准确的知识表示、丰富的先验/背景知识和低成本的知识更新等诸多优势,从而为解决上述问题和增强语义通信系统提供了新的机遇。本文提出了一个专门针对图像数据设计的基于AI大模型的语义通信(LAM-SC)框架。本文的贡献可以总结如下:
1)高精度的语义分割:应用了一个基于大型语义分割模型的知识库(SKB),重点以图像数据的语义分割为例。SKB利用准确的知识表示将原始或非结构化图像分割成不同的语义片段或目标,发送方可对每个语义片段或目标进行单独选择和编码。这使得发送者能够专注于与他们的通信需求相关的特定语义目标。
2)目标导向的语义感知:在语义通信编码器中开发了一种基于注意力的语义整合(ASI)机制,该机制可以准确地衡量由SKB生成的片段的语义重要性。然后,将最重要的片段整合为新的语义感知源数据。因此,ASI 可以实现更精确的语义感知,从而在无需人工干预的情况下保留最关键的语义片段。
3)高效的语义压缩:在语义编码器中提出了一种新的自适应语义压缩(ASC)编码。ASC编码可以屏蔽部分传输的语义特征,屏蔽的比例可根据传输特征的内容进行自适应调整。因此,可以确保进一步消除冗余的语义特征,从而显著减少通信开销。
本文的其余部分组织如下:首先介绍在语义通信系统中实现基于大AI模型的知识库的各种方法。随后,本文介绍了提出的LAM-SC框架,详细说明其关键组件,如SKB、ASI和ASC方法。然后,通过仿真展示了LAM-SC框架的优势。最后,讨论了尚未解决的问题,并对本文进行了总结。
2. 语义通信系统中基于大AI模型知识库
2.1 基于AI大模型的知识库的优势
AI大模型是指具有复杂结构和多头注意力机制的Transformer模型,使其能够处理复杂的AI任务并生成高质量的输出。AI大模型可以通过自监督学习使用无标签数据进行预训练,然后可以通过提示学习或微调将预训练模型应用于各种任务。为了发挥AI大模型在构建通用知识库方面的潜力,从而推动语义通信的发展,本文总结引入AI大模型到知识库中的优势如下:
1)准确的知识表示:当前的大AI模型,如GPT 4.0、Gemini和Llama [9],具有数百千亿个参数,使它们能够从带有多头注意力机制的Transformer模型中学习复杂的知识表示。多头注意力机制可以对语义和知识结构进行深入理解,因此大AI模型可以提供高质量的输入数据语义表示。例如,在大AI模型中,“苹果公司”和“苹果汽水”中的“苹果”一词将被表示为不同的特征。
2)丰富的先验/背景知识:大AI模型在广泛的数据集上进行预训练,如ImageNet、UCF101、Audioset和Wikipedia [10],使其能够从各个领域的大量信息中学习,并存储丰富的先验/背景知识,展现出卓越的泛化能力。它们可以在各种任务上取得高性能,甚至超越它们的预训练知识领域,从而消除了对知识库的频繁更新的需求。
3)低成本的知识更新:大AI模型通常具有预训练的权重,并且可以通过仅使用少量示例进行提示或使用少量标记数据进行微调。诸如P-Tuning、LoRA和prompt-tuning等技术可以实现低成本的更新 [11],减轻了频繁知识更新和不安全知识共享的担忧。
2.2 语义通信系统中AI大模型的设计建议
针对不同类型的语义通信系统(如文本、图像、音频等),本文提出了几种设计方案,允许将大AI模型无缝集成到知识库创建中,如图1所示。
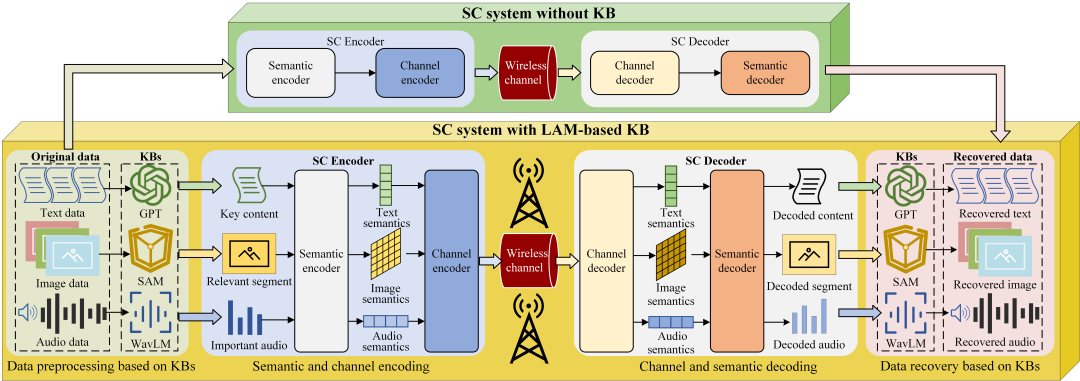
图1 基于AI大模型的知识库在不同语义通信模型中的实现方案。
1)基于GPT的知识库:针对基于文本的语义通信系统,知识库应能够理解文本的内容,并识别各种主题、属性和关系。近年来出现了大规模语言模型,如ChatGPT [9],它可以作为文本数据的语义知识库。ChatGPT是由OpenAI基于GPT-3.5模型开发的AI助手,能够准确理解文本的内容,并对各种问题提供正确的回答。通过将ChatGPT作为文本数据的知识库,可以根据用户的要求从输入文本中提取关键内容。在接收端,语义通信解码器恢复的接收文本数据可以输入ChatGPT以消除语义噪声。此外,可以根据接收用户的偏好重新组织接收到的文本,例如转换成不同的语言。
2)基于SAM的知识库:对于基于图像的语义通信系统,知识库应能够对图像中的各种目标进行分割,并识别它们各自的类别和相互关系。在这里可以应用的一种有前景的AI模型是由Meta AI[12]提出的Segment Anything Model(SAM)。SAM是一个突破性的分割系统,可以在没有任何额外训练的情况下将零样本推广到陌生的图像和目标上。因此,SAM可以被视为图像的完备知识库。在实际系统中,发送端可以使用SAM对输入图像进行分割,并将最重要和有意义的部分选取给语义通信编码器。在接收端,语义解码器输出恢复的图像数据,然后由SAM消除额外的语义噪声或干扰。SAM可以有效地识别和提取图像中感兴趣的语义。
3)基于WavLM的知识库:为了使语义通信系统适用于音频,知识库应能够执行多种音频任务,包括自动语音识别、说话人识别和语音分离。这确保原始音频数据可以被有效地分析并提取语义信息。微软亚洲研究院提出的大规模音频模型WavLM[13]可以成为此应用的潜在解决方案之一。经过94,000小时的无监督英语数据训练,WavLM在一系列语音识别任务和非内容识别语音任务中非常有效。通过使用WavLM作为知识库,发送者可以首先分离和识别来自不同说话者的音频数据,并丢弃背景噪声等不重要的信息。然后,剩余的音频数据由语义通信编码器进行整合和编码。在接收端,可以使用语义通信解码器恢复音频,然后根据用户的要求使用WavLM进行语音降噪和识别。
在基于大模型的三种主要语义通信系统中,基于WavLM的语义通信系统非常适用于实时交互和即时通信,能够实现快速高效的信息交流。相反,基于GPT的语义通信系统在通过文本摘要清晰地传达思想和观点方面表现出色,易于存储、检索和分析文本信息。基于SAM的语义通信系统专注于通过图像传递视觉信息,捕捉复杂的细节、空间组织和颜色,并准确表达表情、情感和非语言线索,以实现更直观的沟通体验。
3. LAM-SC框架的架构
将AI大模型引入到语义通信系统中是在基于图像的语义通信系统中实现更精确的语义感知和通用知识库的一种有前景的解决方案。在本节中,介绍了基于图像数据的LAM-SC框架,该框架将SAM模型纳入到语义通信系统中,并展示了LAM-SC框架的工作流程,如图2所示。
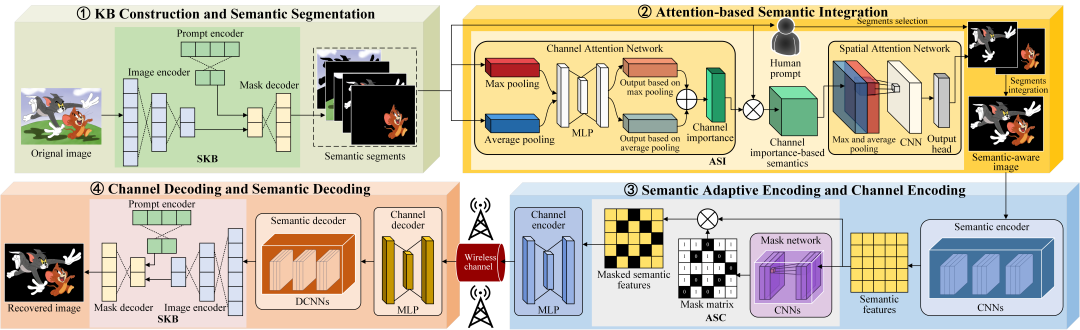
图2 所提出的LAM-SC框架的示意图。
3.1 LAM-SC框架简介
1)知识库构建和语义分割:为了实现对没有经过训练的知识库的任何原始图像进行语义分割,本文应用SKB对输入图像中每个语义目标的识别和分割。这个过程涉及分析图像所传达的视觉信息,以识别每个单独的目标。最后,产生了多个语义片段,其中每个片段只包含一个语义目标。
2)基于注意力的语义整合:ASI可以用来模拟人类感知,通过通道和空间注意力来选择最值得关注的语义片段。此外,本文还提供了一种直接获取感兴趣的语义片段的人类提示方式。这里,人类提示是指基于人的意图的选择结果。最后,所选片段可以合并为新的语义感知图像。。
3)语义自适应编码和信道编码:语义感知图像通过语义编码器转换为语义特征。在这里,语义编码器是基于卷积神经网络(CNNs)构建的,其具有出色的图像特征提取能力。此外,根据语义信息的内容,ASC可以自适应地屏蔽不重要的特征。然后,基于多层感知机(MLP)构建的信道编码器可以用于对物理信道进行信号编码和调制。
4)信道解码和语义解码:在这些模块中,当传输的信号通过物理信道到达接收端时,信道解码器进行信号解调和解码,然后获得语义特征。在这里,信道解码器采用MLP架构。接下来,由逆卷积网络(DCNN)组成的语义解码器对语义特征进行解码,从而恢复图像数据。然后,可以在恢复的源图像上再次使用SKB来准确地识别和分割目标,旨在评估和确认感兴趣的语义的完整性。
3.2 SKB
为了在没有特定训练的情况下实现对任意输入图像的精确图像语义分割,在提出的LAM-SC框架中采用了SAM作为知识库,即SKB,如图2所示,它处理图像语义分割过程。SAM是一个革命性的分割系统,它在最大和最全面的数据集Segment Anything 1-Billion(SA-1B)上进行了训练,该数据集包含了超过10亿个掩码和1,100万张经过许可和隐私保护的图像[12]。这一突破性的系统可以成功地将零样本分割应用于以前未见过的图像或目标,而无需额外的知识和训练。
SKB采用高效的基于Transformer的架构,专为自然语言处理和图像识别任务而设计[12]。该系统包括用于特征提取的基于视觉Transformer的图像编码器,用于用户参与的提示编码器,以及用于分割和生成置信度分数的掩码解码器。因此,本文应用SAM自动实现目标分离,产生多个语义片段以供进一步分析和处理。
3.3 ASI
注意力机制模仿人类视觉,专注于关键细节,忽略无关内容。ASI引入了注意力机制来识别和加权图像中重要目标,它由两部分组成:
1)通道注意力网络:使用通道注意力网络,可以从语义分割中提取低层语义。每个分割被视为一个信道,并进行全局池化和均值池化操作。然后将结果输入到MLP网络中来评估信道的重要性。将MLP的输出结合起来确定语义的重要程度,然后将其与语义分割相乘,基于通道重要性的语义结果。
总之,ASI能够直观地识别和保留原始图像中对人类通常更感兴趣的关键目标,即使在没有任何人类的参与下也能实现这一目标。
3.4 ASC
本文提出了ASC方法,该方法从语义级别自适应地屏蔽传输的语义特征,有效地减少了冗余数据,并显著降低了通信开销。如图2所示,本文利用一个可学习的掩码网络生成掩码矩阵,从而消除了编码的语义特征中的不重要数据。在传输过程中,编码的语义特征被输入到掩码网络中,该网络输出一个相应的由0或1组成的掩码矩阵。然后将语义特征与掩码矩阵相乘,将一部分不重要的特征置为0,从而得到屏蔽后的语义特征。
总之,通过将ASC应用于语义传输过程,可以保留重要的语义特征,同时移除多余的语义特征,从而大大减少通信开销。
4. LAM-SC框架的训练
在本节中,展示了如何训练提出的LAM-SC框架,如图3所示。值得注意的是,SKB中的SAM是一个预先训练好的AI大模型,不需要进行训练。
1)基于人类经验的ASI训练:如前所述,提出的ASI的目标是模拟人类感知,在原始图像中识别感兴趣的目标,并生成与人类偏好相对应的语义感知图像。为了实现这一目标,本文记录人类感兴趣的语义作为经验,这构成了注意力网络的基础训练,包括通道注意力网络和空间注意力网络。在这个经验库中,语义分割可以作为注意力网络的输入样本,而通过人类提示创建的语义感知图像可以看作是相关标签。通过在经验库上进行监督学习,注意力网络可以有效地适应人类行为,并做出与人类感知非常相似的决策。
2)基于交叉的语义通信编码器和解码器训练:SC编码器由语义编码器和信道编码器组成,而SC解码器由信道解码器和语义解码器组成。首先,使用原始语义特征和恢复语义特征之间的差异作为损失函数来指导信道编码器和解码器的训练。然后,使用原始图像和恢复图像之间的差异作为损失函数来指导语义编码器和解码器的训练。本文采用交叉训练策略来实现信道编码器/解码器和语义编码器/解码器模型的学习。具体地,首先训练信道编码器/解码器,然后冻结其参数,然后训练语义编码器/解码器。接着,冻结语义模型参数并再次训练通道模型。重复这个过程,直到整个 SC 模型收敛。
3)ASC训练: 为了生成准确反映语义特征重要性的掩码数组,本文提出了一种掩码网络和SC模型(即信道/语义 编码器/解码器)的联合训练方法,其中SC模型和注意力网络的参数被冻结。训练过程包括以下步骤:首先,原始的和经过压缩的语义特征都被传输。然后,这两组语义特征分别进行解码。接下来,使用原始语义和压缩语义的恢复图像之间的差异被用作掩码网络的损失函数,使其能够学习如何产生能够最小化该差异的最优掩码矩阵。
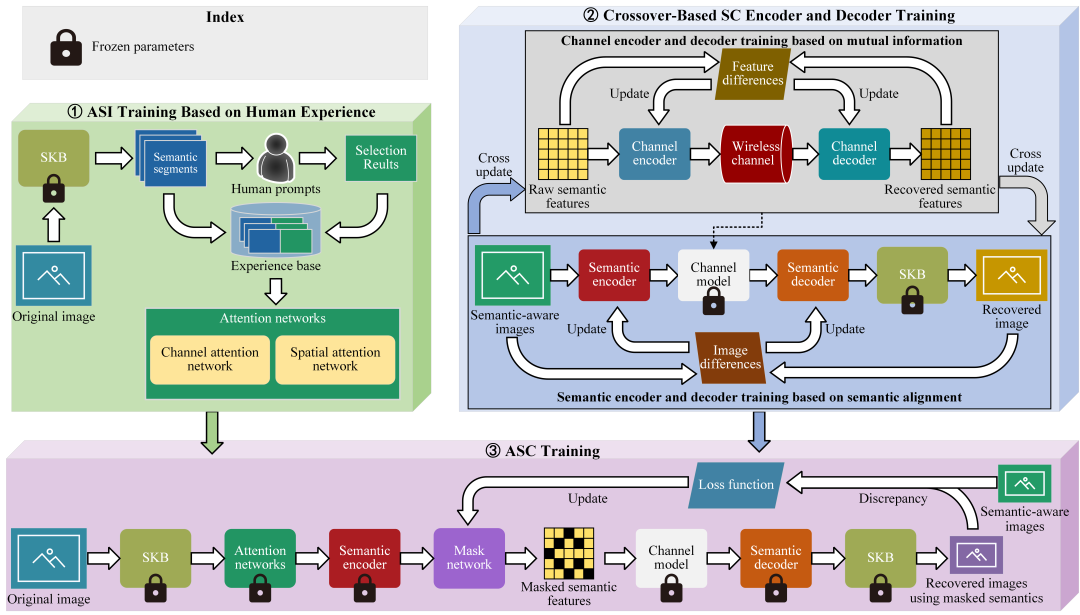
图3 所提出的LAM-SC框架的训练过程。
5. 仿真结果
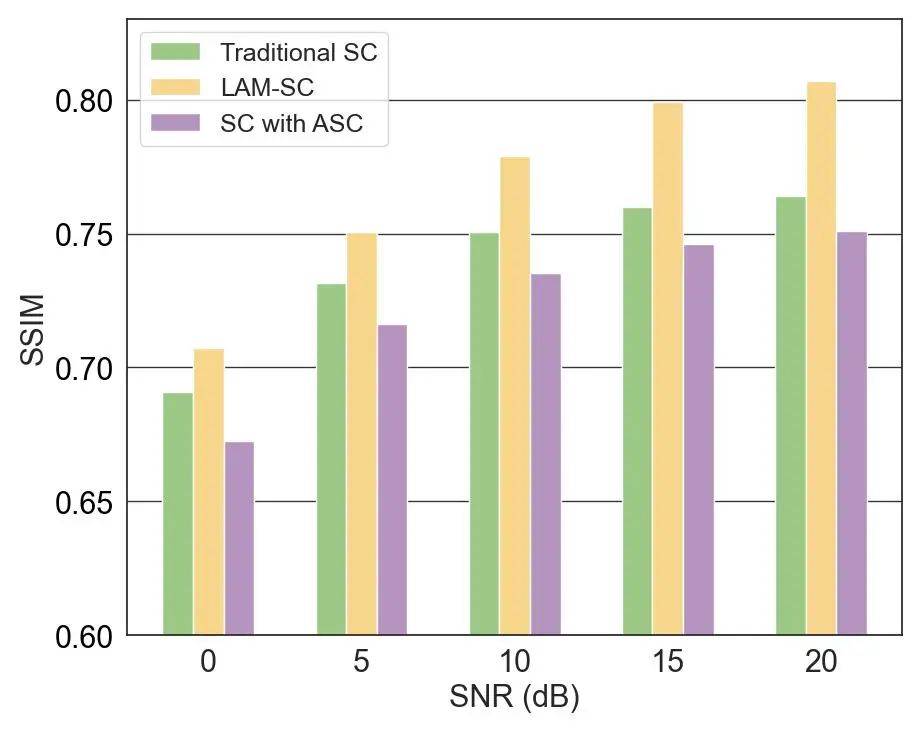
6. 开放性问题
7. 结论
本文介绍了知识库的重要性和组成,并讨论了当前语义通信系统中知识库方案存在的问题。为了解决这些问题,本文提出引入AI大模型构建知识库,并探讨了几种基于AI大模型的方案,以实现不同语义通信系统中的知识库。然后,提出了一个以图像数据为重点的LAM-SC框架,在其中将SAM模型应用于知识库,实现高质量的语义分割,并提出了ASI作为一种新的语义感知源,用于集成分割的语义。此外,还提出了ASC来减少语义传输中的通信开销。最后,进行了仿真实验,以证明所提出的LAM-SC框架的有效性。