大语言模型用于会议摘要
概述
○ 本研究旨在使用大型语言模型(LLM)有效构建适用于实际应用的会议摘要系统。
○ 通过评估和比较各种闭源和开源的LLM,包括GPT-4、GPT-3.5、PaLM-2和LLaMA-2,发现大多数闭源LLM在性能方面表现更好。
○ 然而,即使在零样本场景下,较小的开源模型(如LLaMA-2的7B和13B)仍然能够达到与大型闭源模型相媲美的性能。
○ 考虑到闭源模型只能通过API进行访问的隐私问题,以及使用经过微调的闭源模型的高昂成本,能够实现竞争性性能的开源模型在工业领域更具优势。
○ 在性能、成本和隐私问题之间取得平衡,LLaMA-2-7B模型在工业应用中具有更高的潜力。
○ 总之,本文提供了关于使用LLM进行实际商务会议摘要的实用见解,揭示了性能和成本之间的权衡。
重要问题探讨
1. 大型语言模型在组织会议摘要任务中的输入限制是什么?为什么这限制会成为问题?答:大型语言模型在处理长文本时会有输入限制,也就是一次只能处理一定数量的词。由于组织会议的文本通常较长,这些限制使得大型语言模型无法考虑到整个会议的内容。
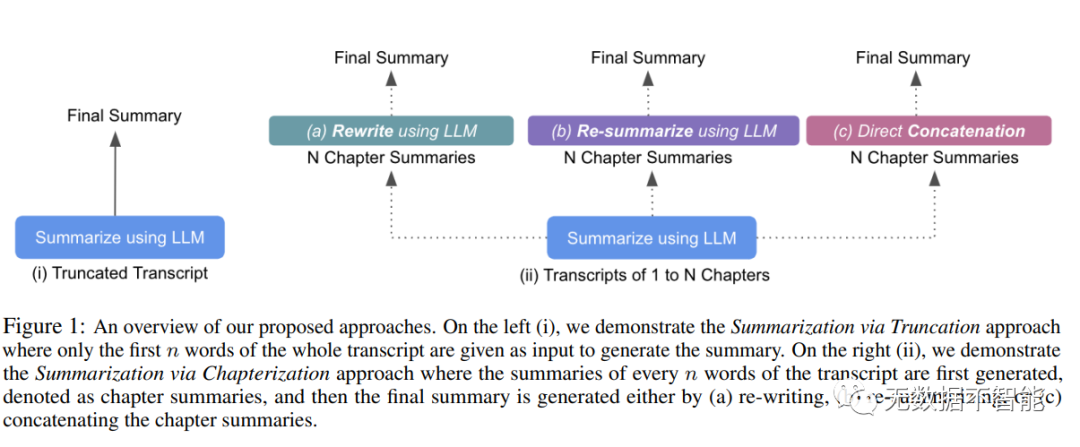
2. 针对大型语言模型在处理长文本时的输入限制,论文提出了哪两个方法?请分别描述它们的原理和应用情景。答:论文提出了两个方法来应对大型语言模型在处理长文本时的输入限制:截断式摘要和章节摘要。截断式摘要是只将会议记录的前n个词作为输入,从而绕过输入限制。章节摘要则是将会议记录拆分成多个章节,每个章节分别进行摘要生成。
3. 在实验中,论文使用了哪些数据集进行模型评估?这些数据集与组织会议摘要任务相关吗?答:论文使用了AMI、ICSI、MeetingBank和QMSUM这四个数据集进行模型评估。与其他数据集不同,这些数据集都包含了组织会议记录,因此与组织会议摘要任务相关。
4. 在模型评估中,不同的大型语言模型在各个数据集上表现如何?是否有一种模型在所有数据集上表现最好?答:不同的大型语言模型在不同的数据集上表现有所不同。在评估各个数据集时,GPT-4模型通常表现最好,其次是GPT-3.5模型,而PaLM-2模型的性能相对较差。同时,LLaMA-2模型取得了竞争性的性能,7B模型的性能几乎与13B模型相当。
5. 论文中还通过案例研究进一步探讨了大型语言模型的性能。请描述模型在上下文长度和提示变化时的表现结果。答:在案例研究中,研究人员调查了大型语言模型在不同上下文长度和提示变化时的性能。结果发现,在最大输入序列长度从2500增加到5000时,并不一定会提高性能。同时,不同提示也会对结果产生影响,例如提示生成较长摘要时,会导致生成的摘要长度增加,性能下降。
6. 论文中的研究有什么实际应用和意义?它为构建现实世界的会议摘要系统提供了什么启示?答:论文的研究目标是为构建现实世界中的会议摘要系统提供最有效的模型。通过对不同大型语言模型的评估,研究人员能够确定在实际应用中最适合的模型,并针对输入限制和提示变化等问题提供了解决方案,为构建现实世界的会议摘要系统提供了启示。
7. 论文研究的局限性和未来可能的改进方向是什么?答:论文的局限性在于没有对数据集的摘要内容进行深入的分析,因此无法确定摘要内容对结果的影响。未来的改进方向可以是进一步分析数据集中摘要内容的分布情况,以更好地理解结果差异的原因,并开展更多的定性评估,来深入探讨大型语言模型在组织会议摘要任务中的应用潜力。
论文链接:https://arxiv.org/abs/2310.19233.pdf
读者可添加笔者微信fanqie6655
加入技术交流群