基于AI大模型的语义通信
论文分享
GenAINet通信大模型
语义通信(SC)是一种新兴的智能范式,为未来的各种应用提供了解决方案,如元宇宙、混合现实和万物互联。现今大多数AI驱动的语义通信系统模型都以设计高效的通信模型为中心,这些模型严重依赖于语义通信的编码器和解码器来提取和解释语义。尽管这些方法能够从非结构化数据源中提取语义信息,但它们并没有充分利用知识库的潜在好处。
为了解决上述问题,江沸菠教授团队提出了一个专用于图像数据的基于AI大模型的语义通信框架(LAM-SC)。设计了基于SAM的知识库(SKB),并提出了一种基于注意力的语义集成(attention-based semantic integration, ASI)方法和一种自适应语义压缩(adaptive semantic compression, ASC)编码方法。LAM-SC框架展示了基于AI大模型的知识库开发在未来语义通信中的重要性。
Large AI Model-Based Semantic Communications
Feibo Jiang1, Yubo Peng2, Li Dong3, Kezhi Wang4, Kun Yang5, Cunhua Pan6, Xiaohu You6,7,8
1Hunan Provincial Key Laboratory of Intelligent Computing and Language Information Processing, Hunan Normal University
2School of Information Science and Engineering, Hunan Normal University
3Changsha Social Laboratory of Artificial Intelligence, Hunan University of Technology and Business
4Department of Computer Science, Brunel University London
5School of Computer Science and Electronic Engineering, University of Essex
6National Mobile Communications Research Laboratory, Southeast University
7Frontiers Science Center for Mobile Information Communication and Security, Southeast University
8Purple Mountain Laboratories
原文链接:https://arxiv.org/abs/2307.03492
1. 背景:
语义通信作为一种新的智能范式,近年来受到了广泛的关注。与传统的通信方法不同,语义通信侧重于确保传输比特或符号的准确性,它优先考虑用最少的数据传递预期的含义。语义通信系统通常包含下列组件:语义编码器(Semantic encoder)、 信道编码器 (Channel encoder)、 信道解码器 (Channel decoder)、 语义解码器 (Semantic decoder)、 知识库 (Knowledge base)。 上述组件可通过应用具有优越的自学习和特征提取能力的深度神经网络(DNNs)来实现。
1.1 语义通信系统中通用知识库的组成
1)有限的知识表示:传统的语义通信系统,通常使用DNNs或KGs作为知识库,通过监督学习从环境中学习。然而,知识库的层次和参数是受限的,并且从环境中收集的标记数据成本高昂。
2)频繁的知识更新:当前的知识库方案需要在环境中知识领域发生变化时,通过训练和共享不断更新知识。这些更新通常会产生巨大的能源和资源成本,从而进一步降低知识库的效率。
3)不安全的知识共享:为避免语义错误,需要分享知识库并确保发送者和接收者在语义上对齐,这需要在不同用户之间频繁传输知识模型。这些知识模型可能包含一些高度敏感的与人类相关的信息,这引入了潜在的隐私和安全风险。
1)准确的知识表示:当前的AI大模型,具有数百千亿个参数,能够从带有多头注意力机制的Transformer模型中学习复杂的知识表示。例如,在AI大模型中,“苹果公司”和“苹果汽水”中的“苹果”一词将被表示为不同的特征。
2)丰富的显眼/背景知识:AI大模型在广泛的数据集上进行预训练,使其能够从各个领域的大量信息中学习,并存储丰富的先验/背景知识,展现出卓越的泛化能力。
3)低成本的知识更新:AI大模型通常具有预训练的权重,并且可以通过仅使用少量示例进行提示或使用少量标记数据进行微调,减轻了频繁知识更新和不安全知识共享的担忧。
本文针对不同类型的语义通信系统(如文本、图像、音频等)提出了几种设计方案,允许将AI大模型无缝集成到知识库创建中,如图1所示。
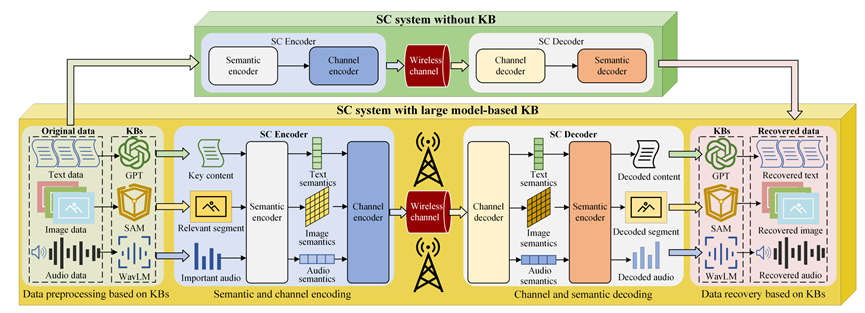
1)基于GPT的知识库:针对基于文本的语义通信系统,知识库应能够理解文本的内容,并识别各种主题、属性和关系。近年来出现了大规模语言模型,如ChatGPT,它可以作为文本数据的语义知识库。
2)基于SAM的知识库:对于基于图像的语义通信系统,知识库应能够对图像中的各种目标进行分割,并识别它们各自的类别和相互关系。在这里可以应用的一种有前景的AI模型是由Meta AI提出的Segment Anything Model(SAM)。
3)基于WavLM的知识库:为了使语义通信系统适用于音频,知识库应能够执行多种音频任务,包括自动语音识别、说话人识别和语音分离。这确保原始音频数据可以被有效地分析并提取语义信息。微软亚洲研究院提出的大规模音频模型WavLM可以成为此应用的潜在解决方案之一。
3. 本文所提LAM-SC框架架构:
将AI大模型引入到语义通信系统中是在基于图像的语义通信系统中实现更精确的语义感知和通用知识库的一种有前景的解决方案。本文提出了LAM-SC框架,将SAM模型纳入到语义通信系统中,工作流程如图2所示。
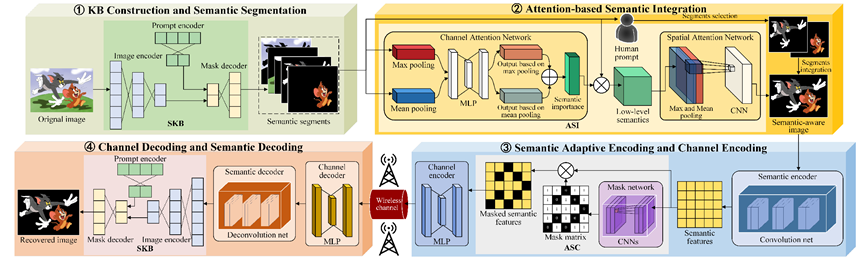
图2. LAM-SC框架的流程
3.1 LAM-SC框架简介
1)知识库构建和语义分割: 为了实现对没有经过训练的知识库的任何原始图像进行语义分割,可以应用SKB来实现对输入图像中每个语义目标的识别和分割。
2)基于注意力的语义整合: ASI可以通过信道注意力和空间注意力模拟人类的感知,选择最值得关注的语义片段。此外,还提供了一种人类提示的方式,可以直接选择感兴趣的语义片段。选择的片段可以合并成一个新的具有语义感知的图像。
3) 语义自适应编码和信道编码:语义感知图像通过语义编码器转换为语义特征。在这里,语义编码器是基于卷积神经网络(CNNs)构建的,其具有出色的图像特征提取能力。基于多层感知机(MLP)构建的信道编码器可以用于对物理信道进行信号编码和调制。
4) 信道解码和语义解码: 在这些模块中,当传输的信号通过物理信道到达接收端时,信道解码器进行信号解调和解码,然后获得语义特征。信道解码器采用MLP架构。接下来,由反卷积层组成的语义解码器对语义特征进行解码,从而恢复图像数据。
3.3 ASI
ASI引入了注意力机制来识别和加权图像中重要目标,它由两部分组成:
1) 信道注意力网络: 使用信道注意力网络,可以从语义分割中提取低层语义。每个分割被视为一个信道,并进行全局池化和均值池化操作。然后将结果输入到MLP网络中来评估信道的重要性。将MLP的输出结合起来确定语义的重要程度,然后将其与语义分割相乘,得到低层语义。
2) 空间注意网络:每个低层语义表示单个分割,无法充分捕捉整个图像的语义。为了解决这个问题,使用空间注意力网络来合并低层语义,得到高层语义表示。具体地,分别对低层语义进行全局池化和均值池化,并沿图像通道维度进行连接,然后应用CNN将所有低层语义集成为高层语义感知图像。
3.4 ASC
本文提出了ASC方法,该方法从语义级别自适应地屏蔽传输的语义特征,有效地减少了冗余数据,并显著降低了通信开销。如图2所示,本文利用一个可学习的掩码网络生成掩码矩阵,从而消除了编码的语义特征中的不重要数据。在传输过程中,编码的语义特征被输入到掩码网络中,该网络输出一个相应的由0或1组成的掩码矩阵。然后将语义特征与掩码矩阵相乘,将一部分不重要的特征置为0,从而得到屏蔽后的语义特征。
4. LAM-SC框架的训练:
本文提出的LAM-SC框架的训练过程如图3所示。简要描述如下:
1) 基于人类经验的ASI训练:本文记录人类感兴趣的语义作为经验,构建了一个经验库。通过对经验数据库的监督学习,注意网络可以有效地适应人类行为,并做出与人类感知非常相似的决策。
2) 基于交叉的语义通信编码器和解码器训练:实施一个交叉训练策略,首先训练通道模型,然后冻结其参数,然后训练语义模型。之后冻结语义模型参数并再次训练通道模型。这个过程可以重复,直到整个SC模型达到收敛。
3) ASC训练: 为了生成准确反映语义特征重要性的掩码数组,本文提出了一种掩码网络和语义通信模型(即信道/语义编码器/解码器)的联合训练方法,其中语义通信模型和注意力网络的参数被冻结。首先,原始的和经过掩码的语义特征都被传输。然后,这两组语义特征分别进行解码。接下来,使用原始语义和掩码语义的恢复图像之间的差异被用作掩码网络的损失函数,使其能够学习如何产生能够最小化该差异的最优掩码矩阵。
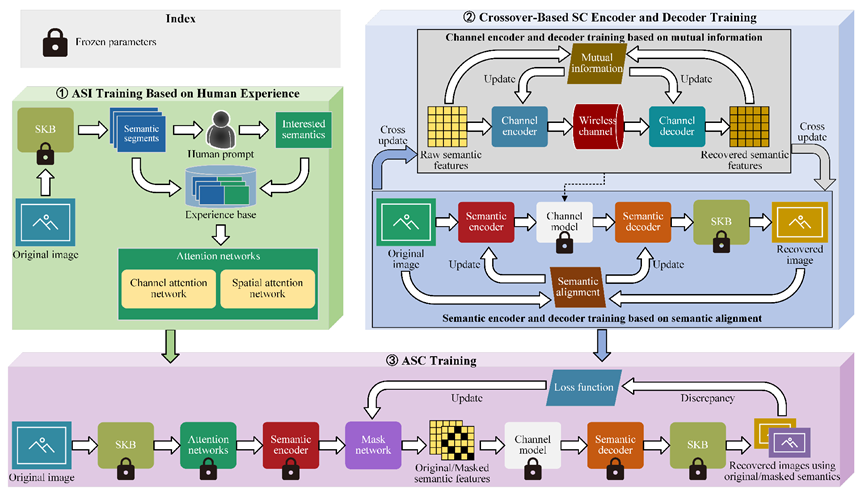
图3. LAM-SC框架的训练过程
本文用VOC2012数据集进行实验验证,比较了LAM-SC方法和传统SC方法。传统的语义通信模型被用作基准,其仅包括语义编解码器,以及信道编解码器。此外,传统的语义通信模型不利用SKB在传输之前分割原始图像。本文使用三个关键指标来评估性能:损失值、峰值信噪比(PSNR)和结构相似性(SSIM)。
模拟结果如图4所示。图4(a)表明在相同的信噪比条件下,与传统的语义通信方案相比,LAM-SC具有更好的收敛结果。图4(b)表明使用LAM-SC传输的图像获得更高的PSNR值,这意味着LAM-SC在传输过程中有效地减小了图像的失真。图4(c)证明LAM-SC保持了传输图像的结构一致性,从而获取了更高的SSIM值。
图4. LAM-SC的仿真结果。(a) 损失与迭代次数。(b)PSNR与信噪比。(c)SSIM与信噪比。
6. 结论:
本文介绍了知识库的重要性和组成,并讨论了当前语义通信系统中知识库方案存在的问题。为了解决这些问题,本文提出引入AI大模型构建知识库,并探讨了几种基于AI大模型的方案,以实现不同语义通信系统中的知识库。然后,提出了一个以图像数据为重点的LAM-SC框架,在其中将SAM模型应用于知识库,实现高质量的语义分割,并提出了ASI作为一种新的语义感知源,用于集成分割的语义。此外,还提出了ASC来减少语义传输中的通信开销。最后,进行了仿真实验,以证明所提出的LAM-SC框架的有效性。
GenAINet公众号简介
GenAINet公众号由IEEE Large Generative AI Models in Telecom (GenAINet) ETI成立,由GenAINet公众号运营团队负责维护并运行。
GenAINet公众号运营团队:
孙黎,彭程晖 (华为技术有限公司)
杜清河,肖玉权,张朝阳,赫小萱 (西安交通大学)
王锦光,俸萍 (鹏城实验室)
编辑:张朝阳
校对:肖玉权