利用大语言模型增强口语话文本理解
读者可添加笔者微信fanqie6655
概述
○ 该研究论文探讨了一种可以利用文本数据进行训练的方法来增强口语理解模型的性能。
○ 通过比较联合音频文本和文本转语音(TTS)两种方法,研究发现从现有文本语料库中获取的未配对文本数据可以提高性能。
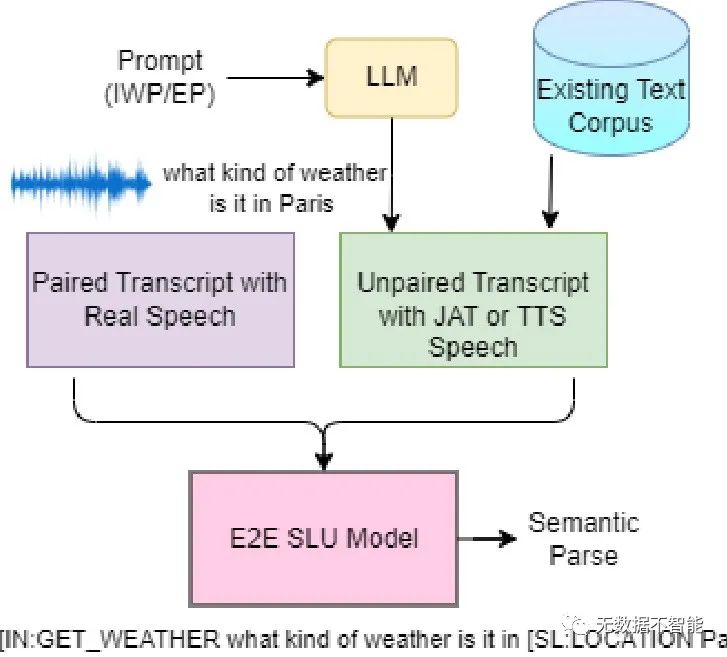
○ 当现有语料库中无法获取未配对文本数据时,借助大型语言模型(LLMs)生成未配对文本数据的方法也被提出,通过生成的文本数据结合联合音频文本和文本转语音进行口语解析,可以显著提高性能。
摘要:口语语义解析(SSP)涉及从语音输入中生成机器可理解的解析树。训练对于现有的应用领域具有鲁棒性的模型,需要匹配的语音-转录文本-语义解析数据,这是昂贵的。本文通过研究可以在没有配对语音的情况下使用转录-语义解析数据(未配对文本)的方法来解决这个挑战。首先,当未配对文本来自现有的文本语料库时,比较了联合音频文本(JAT)和文本转语音(TTS)两种用于生成未配对文本的方法。在STOP数据集上的实验表明,现有和新领域的未配对文本分别提高了2%和30%的绝对完全匹配(EM)。其次,考虑到现有的文本语料库中没有未配对文本的情况。我们提议用大型语言模型(LLMs)提示生成文本解析为S、E、N准则,利用生成的文本与音频文本和文本转语音进行口语语义解析,在已存在和新领域上分别提高了1.4%和2.6%的完全匹配(EM)。
重要问题探讨
1. 什么是SSP(口语语义解析)?它的目标是什么? SSP是指将语音输入转化为机器可理解的语义分析树的任务。它的目标是通过解析语音,理解用户的意图和需求。
2. 为什么需要使用transcript-semantic parse数据进行模型训练? 使用配对的speech-transcript-semantic parse数据可以用于训练SLU模型,但是这样的数据很难获取,而且成本很高。
论文链接:https://arxiv.org/abs/2309.09390.pdf
加入技术交流群