【论文】困惑度能否反映大语言模型在长文本理解中的能力?
* 戳上方蓝字“AI大模型在手”关注我
今天关注到北大研究团队发布一篇探讨困惑度和大模型长下文关系的 Tiny Paper(附录A),阅后觉得这篇论文中的结论值得商榷,在此记录一下,与诸君探讨:
⊙论文点评
▷降低PPL≠更好地理解长文本
▷编者注:这个结论是欠缺说服力
⊙附录A:什么是 Tiny Paper
⊙附录B:什么是 PPL
论文点评
引言:困惑度能否反映大语言模型在长文本理解中的能力?
最近的研究表明,大语言模型(LLMs)具有处理超长文本的潜力。我们发现有许多工作都是以困惑度(PPL 附录B)作为指标来评估LLMs的长文本处理能力。然而,我们在研究中发现 PPL 和 LLMs的长文本理解能力之间没有相关性。

论文链接:
https://arxiv.org/pdf/2405.06105
降低PPL≠更好地理解长文本
PPL更适用于评估语言建模的效果,如语句的连贯性,是一种局部的信息建模能力
长上下文能力更多体现在语义的理解上,是一种捕获长程依赖的能力。
这篇论文的思路很直接,就是通过对比不同的模型,在相同的评测集上,发现它们的上下文能力排名和PPL排名不一致,所以下结论“降低PPL≠更好地理解长文本”。
1)YARN-7B-128K
2)Yi-6B-200K
3)LongLoRA-7B-100K
从PG-19数据集中随机抽样了50本书中的句子,总长度共计76k,在这个数据集上计算了以上三个大模型的PPL,结果如图所示:
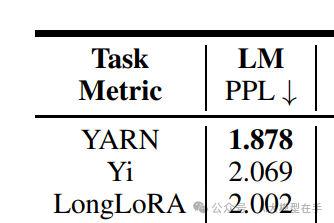
在下游任务中,使用 QMSUM 和 NarrativeQA 两个公开的基准,来评估模型在长问答和长文档摘要方面的性能。
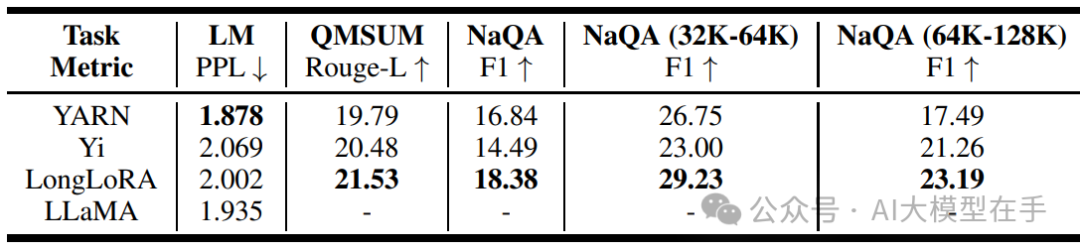
实验结果表明:虽然 YARN 的困惑度( LM 列)最低,为1.878,而 Yi 的困惑度为2.069,LongLoRA的困惑度为2.002,这说明 YARN 在长文本语言建模方面能力比LongLoRA 强。然而,在下游任务中,YARN并没有取得最好的表现。相反,LongLoRA在所有下游任务上都超过了其他模型。
模型在语言建模和下游任务表现之间的不一致表明:尽管困惑度是一个相对公平的评估语言建模的指标,但它并不能很好地预示大模型对长文本理解的能力。在评估一个模型在长文本中的能力时,我们应该关注到PPL是有局限性的,避免过度依赖它。
编者注:这个结论是欠缺说服力
理由如下:
1、对比实验做的不够,只挑了3个模型,完全忽视了这三个模型的架构、训练参数、训练数据之间的差异,因不可控的变量太多,表格中所展现的这点差异不足以说明发现了一个“规律”,可能因为是 Tiny Paper,篇幅有限就没把实验结果贴出来,希望能继续这个工作,把更多的实验结果公布出来。
2、 长上下文能力评估太片面,QMSUM 和 NarrativeQA 都是好几年前的评测数据集(其中 NarrativeQA 是 DeepMind 在2017年发布的),在现在大模型时代,动辄几T十几T tokens 的训练语料中,很多评测集都已经被有意无意的包含进去了,所以在旧的评测集上的表现并不能代表真实的表现,这也是大模型研究的重点方向:如何检测数据是否泄漏、如何更公正的评测大模型的性能等。这篇 Tiny Paper 仅依靠大模型在两个老评测集的表现来衡量大模型的长上下文能力,缺乏说服力。
附录A 什么是Tiny Paper
Tiny Papers 是国际学习表示会议(ICLR)2023年推出的一项新举措,旨在为研究界提供更多样化、互补和易于接近的科研入口。这一举措特别关注于初级研究者,以及来自不同背景的研究人员,使他们能够更容易地参与到ICLR社区中。Tiny Papers 的目标有三个:
创建替代性、补充性和多样化的研究入口,特别是为初学者提供易于接近的途径,以便他们能够享受ICLR社区的氛围。
庆祝机器学习领域的中间突破。
高效地传播想法、发现和观点。
作为一项多样性、公平和包容性(DEI)的举措,Tiny Paper 要求每一份提交的论文至少有一位关键作者符合未被充分代表的少数群体(URM)的标准。这些标准可能包括年龄、性别、性取向、种族或民族背景、地理位置等。此外,经济条件不佳的研究人员和首次提交者也被纳入这一范畴。
Tiny Papers 的提交内容可以包括新颖的简单想法的实现和实验、对已发表论文的后续实验或重新分析,以及关于已发表论文的新视角。提交的论文长度限制在最多两页主要文本,但参考文献、附录和URM声明部分不计入页数限制。
ICLR 2023年的Tiny Papers取得了成功,因此,ICLR 2024年也计划继续这一举措,并做出了一些改进,例如提前截止日期,并指派了专门的Tiny Papers主席,以确保该项目的成功。
这一举措的目的是鼓励更广泛的参与和多元化的观点,在科研界推动更多样化的声音和想法
编者注:正因如此,Tiny Paper 中的观点并不一定成熟,实验也不一定充分,要仔细甄别,不可盲目相信。另外 ICLR 本身也是较为「年轻」的学术会议,目前为止共举办了两届。
附录B 什么是 PPL
大家在使用智能助手、搜索引擎或者阅读新闻推荐时,有没有想过,这些智能系统是怎么理解我们说的话,然后给出回应的呢?这背后就有一个神秘的“大脑”——语言模型。今天,就来给大家揭秘一下,我们是如何衡量这个“大脑”性能的一个关键指标——PPL。
PPL,也就是“平均感知困惑度”(Perplexity),这个名字听起来是不是有点玄乎?其实,它就像是我们考试时候的“难题指数”。PPL越小,说明这个语言模型遇到的“难题”越少,理解语言的能力就越强。
想象一下,如果给你一篇小学一年级的课文,你是不是读起来毫不费力,PPL就很低;但如果是一篇博士论文,那可能就满头问号了,PPL就高。同理,对于语言模型来说,PPL越低,就说明它在理解各种语言表达时越得心应手。
简单来说,PPL衡量的是语言模型预测下一个词的“不确定性”。在自然语言处理领域,我们希望语言模型能够像我们人类一样流畅地理解和生成语言,所以我们会不断地优化模型,让它的PPL越来越低,这样我们就能得到更加智能、更加懂我们的AI了。计算困惑度的公式如下:
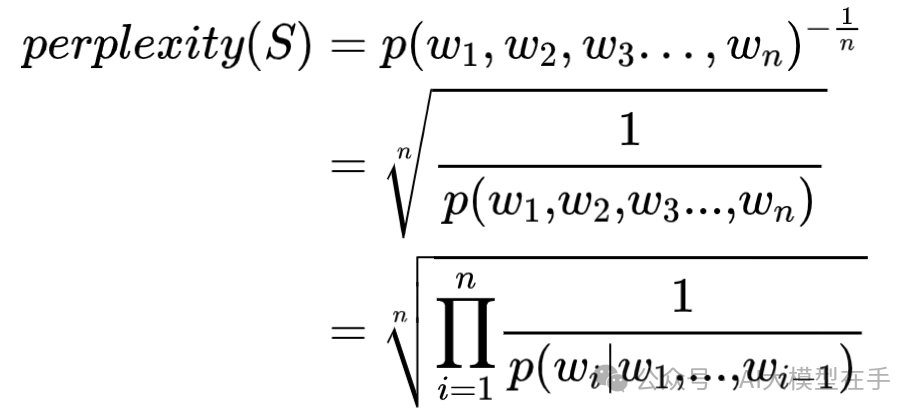
在测试集上得到的困惑度越低,说明语言模型的效果越好。通过上面的公式也可以看出,困惑度实际上是计算每一个单词得到的概率导数的几何平均,即模型预测下一个单词时的平均可选择的单词数量。
下面举一个简单的小例子,假设现在词汇表中有三个单词:,则训练好的bigram语言模型的参数值为:
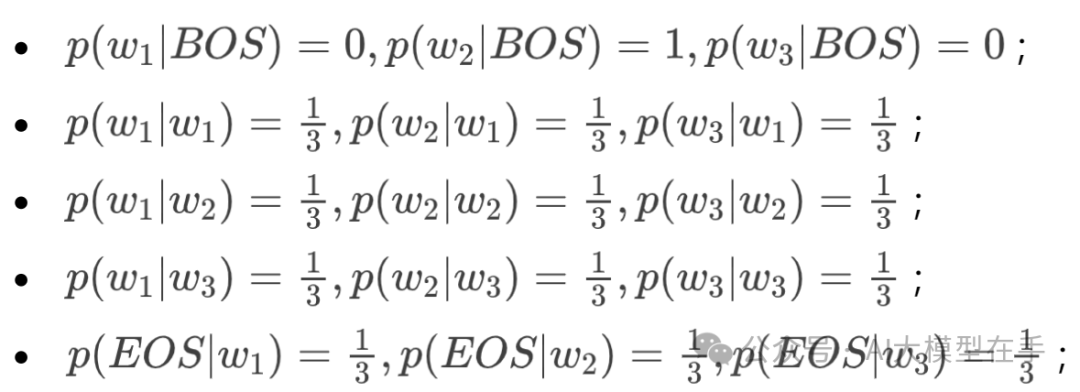
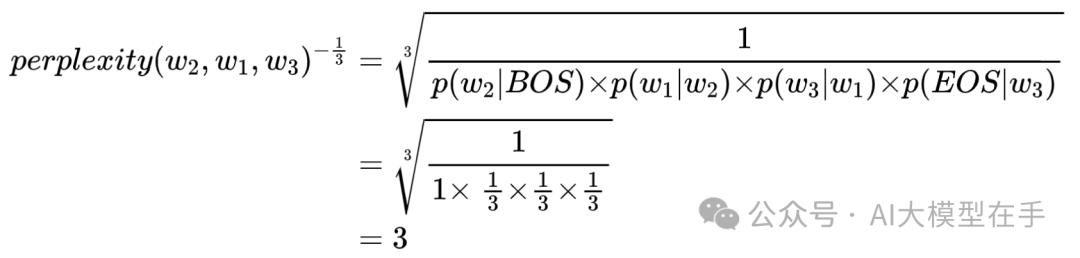
此时训练好的bigram语言模型的困惑度为3,也就是说,在平均情况下,该模型预测下一个单词时,有3个单词等可能的可以作为下一个单词的合理选择。当然上面的bigram语言模型设置的参数值仅仅是为了举例方便。
上面都是在计算一个句子的困惑度,如果测试集中有n个句子,只需要计算出这n句子的困惑度,然后将n个困惑度累加取平均,最终的结果作为训练好的语言模型的困惑度。
往期推荐
点个在看,转发那就更好了!