近日,中科院上海药物所郑明月团队于2023年4月在J Cheminform上发表了一篇关于筛选由AI生成分子的论文:《MolFilterGAN: a progressively augmented generative adversarial network for triaging AI-designed molecules》。作者提出一种名为MolFilterGAN的模型,旨在优先选择具有潜在药物开发价值的分子结构,提高分子筛选的效率和准确性,从而加速药物发现的过程。药物化学家一直追求着从头开始设计出符合特定要求的分子。然而,由于药物-靶标相互作用的复杂性和对结构-性质关系的理解不足,很难直接从分子活性、物理化学性质或ADME性质中设计出化学结构。深度生成模型提供了一种新的方法,可以生成符合要求的分子结构。为了评估生成的分子,人们使用了多种度量标准,如有效性、独特性、新颖性和多样性等。此外,如何从生成的分子中选择用于后续合成和生物评价的分子也是一个重要的问题。目前,研究人员已经开发了许多基于机器学习的度量标准,如QED、SA、Fsp3和MCE-18,可以快速评估分子的潜力。然而,这些度量标准和方法并不适用于所有场景。同时,对于由AI设计的分子进行筛选时,仍然存在一些问题需要解决。
本研究探讨了现有度量标准或筛选模型在八个基准数据集上的有效性,并提出了MolFilterGAN来区分不同来源的分子的潜力,从而加速虚拟筛选进程。MolFilterGAN使用对抗网络来生成更像已知药物或生物活性分子的分子,并通过逐步增强策略产生更多样化和平衡的负样本,以提高鉴别器的区分和泛化能力。最终,鉴别器的鉴别结果可以作为深度生成模型的分子筛选度量标准。
为了比较现有的分子筛选度量标准,作者准备了八个不同的数据集,以代表AI设计分子、可合成分子、生物活性分子和已批准药物的化学空间。具体来说,从三种生成方模型中分别采样1万个分子:基于图的遗传算法(GA)、使用经过过滤的ZINC数据库训练的GENTRL(VAE-ZINC-S)和使用ZINC数据库训练的LSTM模型(LSTM-ZINC)。从ZINC和REAL数据库中各抽样了1万个分子,以代表实际可得到的化学空间。此外,从ChEMBL和中国天然产物数据库中分别抽样了1万个分子,代表生物活性化学空间。最后,从Cortellis中收集了通过第三期临床试验的748个候选药物,以代表药物化学空间。
为了减少数据偏差,本研究删除了具有长的脂肪链、多个羟基基团、分子量大于750以及原子数小于10的分子。然后将所有的分子转换为SMILES并构建词汇表用于表征字符,然后输入到MolFilterGAN模型。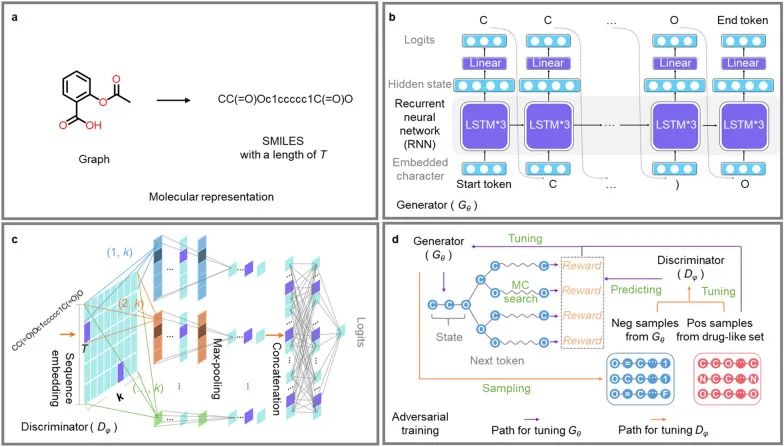
图1 数据处理与MolFilterGAN模型
如图1所示,生成模型使用LSTM搭建,判别模型使用CNN模型搭建。对于生成器(Gθ),输入和输出都是 SMILES 字符串。对于鉴别器( Dφ),输入是一个 SMILES 字符串(分子),而输出的是鉴别器判定为来自“真实”样本的概率。此外,在用于测试之前,MolFilterGAN在大规模数据集上进行预训练。
研究发现,大多数来自生物活性化学空间或药物化学空间的化合物符合RO5的规则,如图2a、b所示。但是RO5标准在其他基准集上表现不佳,因此在筛选候选药物时,RO5可能会出现过高的假阳性率。另外,作者发现QED的评分结果出现了误导性的趋势,其中ZINC和REAL分别获得了比ChEMBL、CNPD和Cortellis-Drugs更高的评分(如图2c、d所示),这意味着在一些商业化合物库用于药物筛选时,这些评价方法可能会适得其反。此外,BNN(AE+GCNN)能够很好地区分药物化学空间和可合成的化学空间,在生物活性库(ChEMBL、CNPD)的评分分布也符合预期(如图2e所示)。但是,当将其应用于过滤生成模型生成的分子时,BNN在生成库GA和VAE-ZINC-S也获得了高分,这意味着它可能有助于HTS或vHTS,但在过滤生成模型得到的分子时,可能会出现高误报率。如图2e,MolFilterGAN模型在不同化学空间的基准数据集上表现出色,能够很好地区分药物或生物活性分子和可合成分子。相比其他方法,该模型在VAE-ZINC-S或GA的得分上有所降低,这表明MolFilterGAN能够过滤掉低质量的生成化合物,减少高假阳性率的问题。研究结果表明,MolFilterGAN在区分不同来源的化合物方面表现更好,适合评估受益于其稳健的判别能力的分子。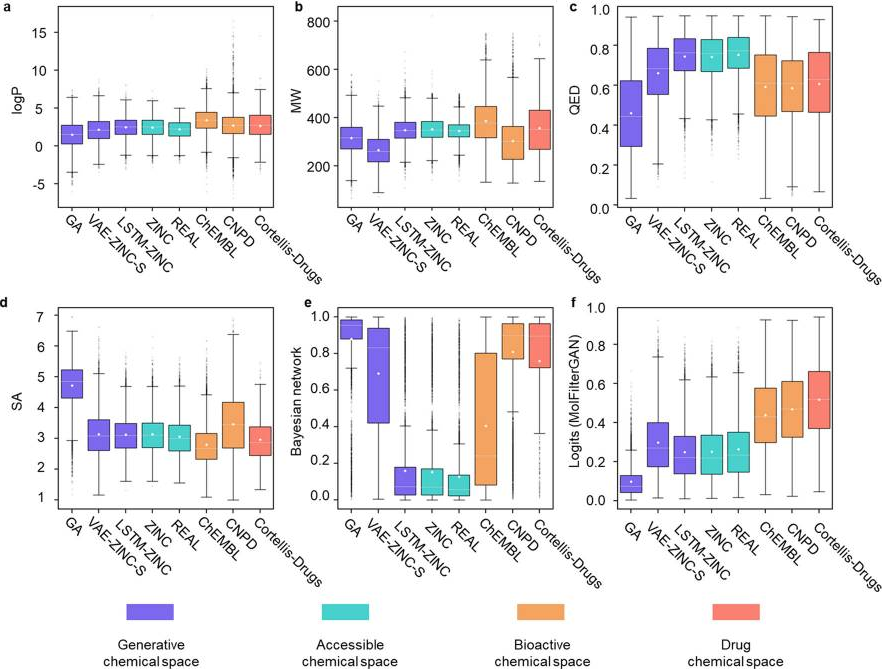
图2 分子过滤指标和模型在基准数据集上的表现
相对于BNN,作者认为MolFilterGAN的优势可能归因于在训练中逐渐增强的判别能力,使得负样本数据更具多样性和平衡性。作者比较了两种分子采样方法,分别是从ZINC数据库中随机采样分子和从MolFilterGAN生成器中逐步采样分子。如图3所示,模型生成的负样本在分子量、clogP、氢键受体、氢键供体和可旋转键的数量分布上比ZINC数据集更广。此外,这些负样本逐渐变得越来越难以被判别器区分,因此MolFilterGAN的判别和泛化能力得到了增强。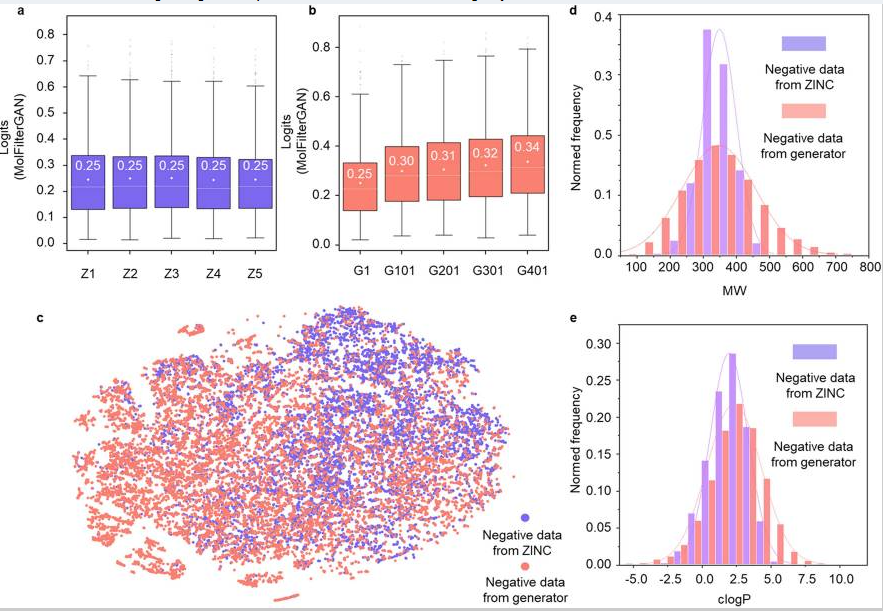
图3 两种采样方式的分子化学空间分布
4.3 过滤生成分子的效率
在先前的报道中,GENTRL模型生成了30,000种化合物中,通过各种内部过滤方法与专家的目视检查相结合,最终选出6种化合物用于后续合成和生物学评估。作者只使用了MolFilterGAN和传统的基于结构的对接对化合物进行过滤。如图5a所示,仅使用分子对接评分,这3种活性化合物中没有一种排名前6。当与MolFilterGAN相结合使用时,活性化合物cpd.1和cpd.4可以成功地排在前6位。结果表明MolFilterGAN可以作为一种有用的筛选方法用于从头设计分子。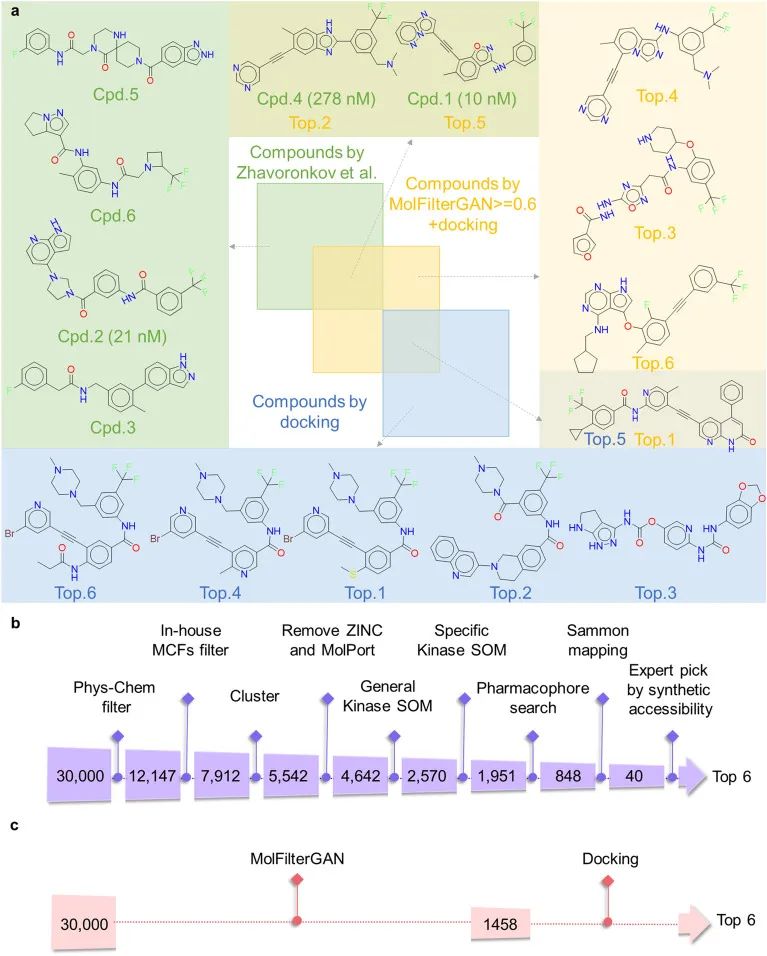
图4 MolFilterGAN在实际应用中的表现
作者将模型在LIT-PCBA数据集上进行了评估,并与传统的过滤指标QED和SA进行了比较。结果表明,QED和SA的性能低于随机猜测的得分,这可能会导致筛选的效果变差。相比之下,MolFilterGAN 适用于多种不同靶点类型的活性分子筛选。此外,该模型可能已经学习到了一些重要的特征,可以识别分子是否具有与生物活性相关的结构。MolFilterGAN可以与其他方法(如对接和结合亲和力预测模型)相结合使用。这些结果表明,MolFilterGAN是一种有前途的工具,可以帮助加速药物发现的过程。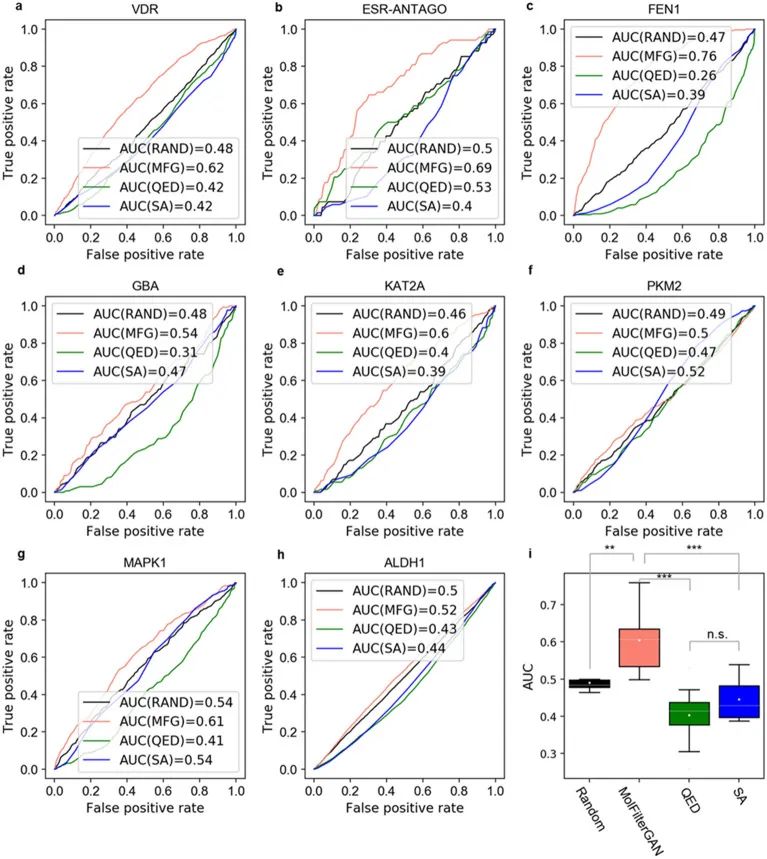
图5 MolFilterGAN、QED和SA在LIT-PCBA数据集上的评估本文研究了基于人工智能的分子设计方法在药物发现中的应用,特别是如何从巨大的化学空间中筛选出具有潜在药物开发价值的分子结构。研究发现,传统的分子过滤指标和基于人工智能的模型难以很好地区分来自不同来源的分子。为了解决这个问题,研究者基于生成对抗网络开发了一种新的分子过滤方法MolFilterGAN,该方法可以区分生物活性/药物分子和模型生成的分子。实验结果表明,MolFilterGAN在筛选潜在的生物活性分子方面具有很好的效果,并且可以适用于多种不同靶点类型的活性分子筛选。这些结果表明,MolFilterGAN是一种有前途的工具,可以帮助加速药物发现的过程,并减少药物分子的手动评估。
Liu X, Zhang W, Tong X, et al. MolFilterGAN: a progressively augmented generative adversarial network for triaging AI-designed molecules. J Cheminform. 2023;15(1):42. Published 2023 Apr 8. doi:10.1186/s13321-023-00711-1https://github.com/MolFilterGAN/MolFilterGAN
本文系AIDD Pro接受的外部投稿,文中所述观点仅代表作者本人观点,不代表AIDD Pro平台,如您发现发布内容有任何版权侵扰或者其他信息错误解读,请及时联系AIDD Pro (请添加微信号sixiali_fox59)进行删改处理。
原创内容未经授权,禁止转载至其他平台。有问题可发邮件至[email protected]

关注我,更多资讯早知道↓↓↓
本文由“公众号文章抓取器”生成,请忽略上文所有联系方式或指引式信息。有问题可以联系:五人工作室,官网:www.Wuren.Work,QQ微信同号1976.424.585
本文由“公众号文章抓取器”生成,请忽略上文所有联系方式或指引式信息。有问题可以联系:五人工作室,官网:www.Wuren.Work,QQ微信同号1976.424.585
code/s?__biz=MzkzNjIzMTU0Nw==&mid=2247540565&idx=1&sn=a26643f7637d70168041919d24542c95&chksm=c2a3c841f5d44157889f0298982ef39e361499b524a11284baec5a69b52ba8d7d397a88144cd#rd

