AI+计算机视觉-1
尝试一些开源的AI CV方案。基础架构使用Azure GPU VM。
一、静图生动图
使用i2vgen-xl模型验证效果
原静图:

生成的动图(下面视频是录制的动图,并且录制了三遍):
效果还可以,但现目前现有的开源模型都无法生成复杂的、长时间连续的Video,比Sora差距还是很大的。
二、
使用如下开源项目:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings
LoRA (Low-Rank Adaptation) 模型,称为小稳定扩散模型,在传统检查点模型中进行了细微调整。LoRA模型的链接包括:像素艺术、幽灵、Barbicore、赛博格以及受Greg Rutkowski启发的风格。LoRA模型不能独立运作,它需要与模型checkpoints协同工作。LoRA通过对相应模型文件引入微妙变化,带来风格上的差异。此外,随着SDXL的发布,StabilityAI已经确认,他们期望在SDXL v1.0基础模型上,LoRA将成为增强图像最流行的方式。LoRA模型可以在https://civitai.com/ 或 https://huggingface.co/ 上找到。
例如我们可以下载下面的LoRA。
https://civitai.com/models/331116?modelVersionId=464939
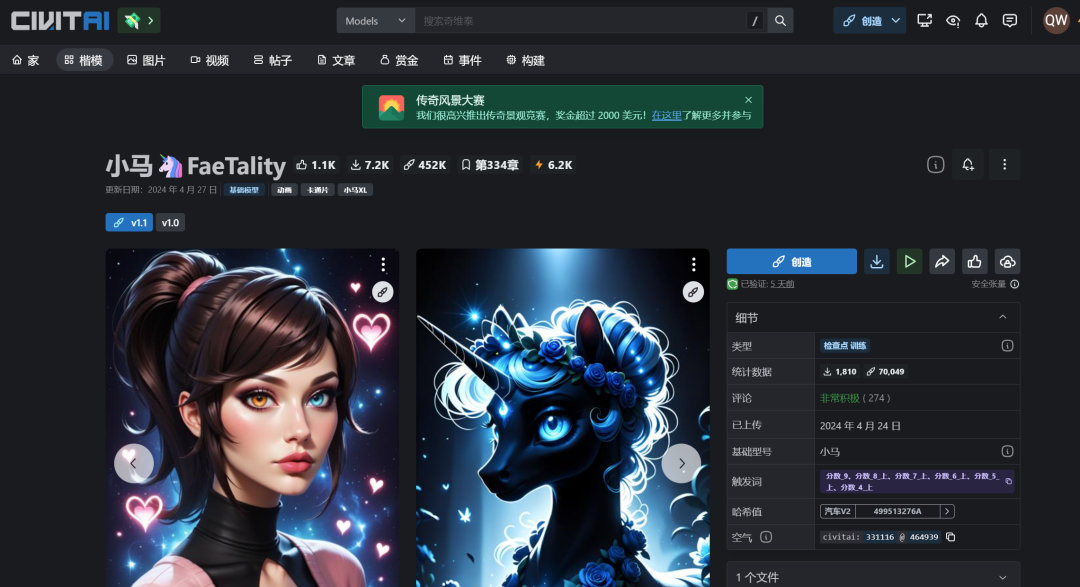
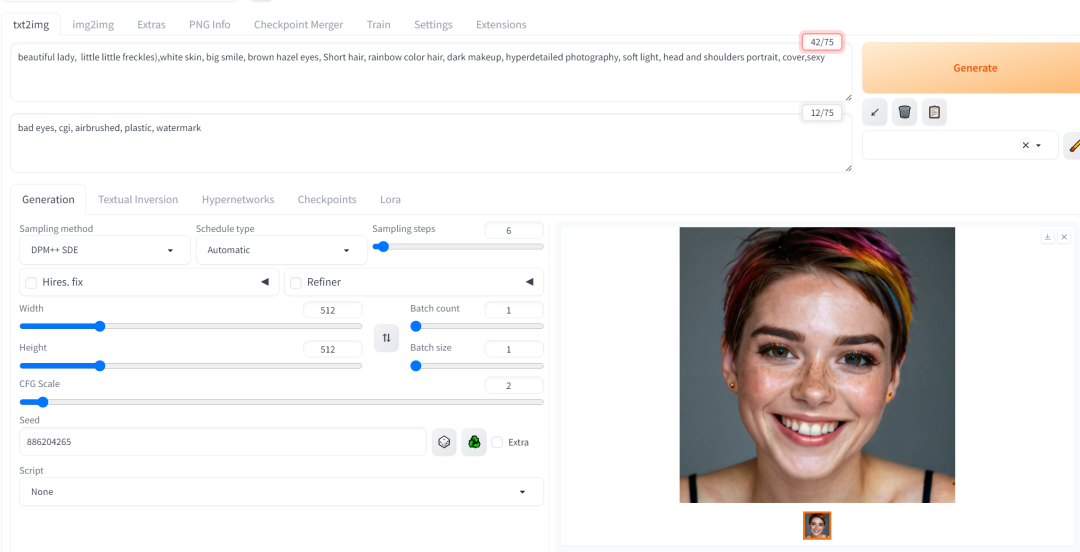
运行

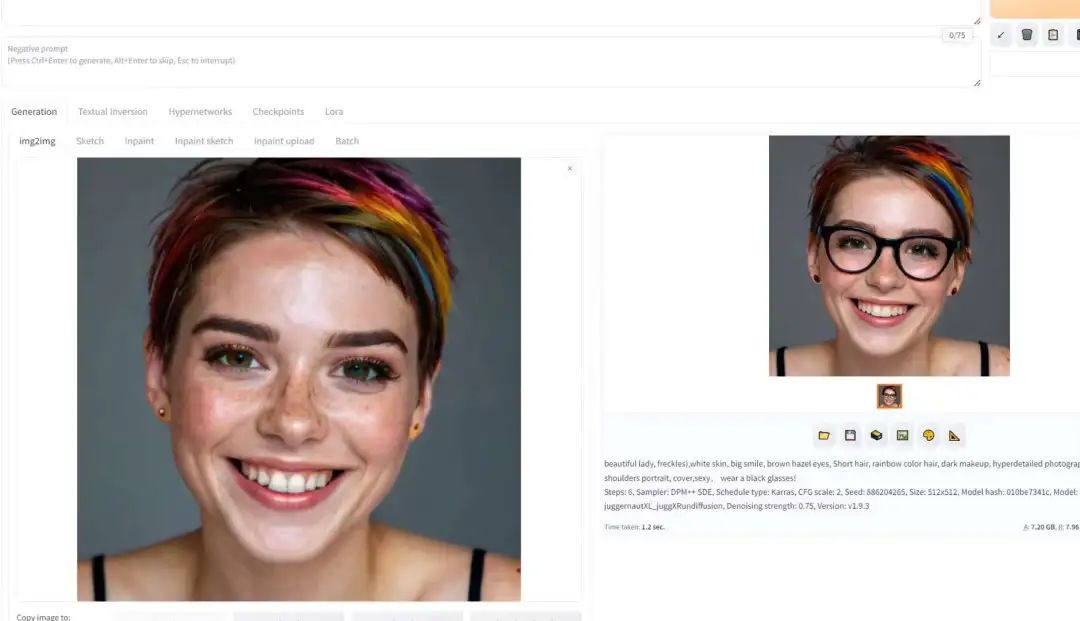
接下来,验证图生图,在原图上增加个眼镜,图别的部分不变:
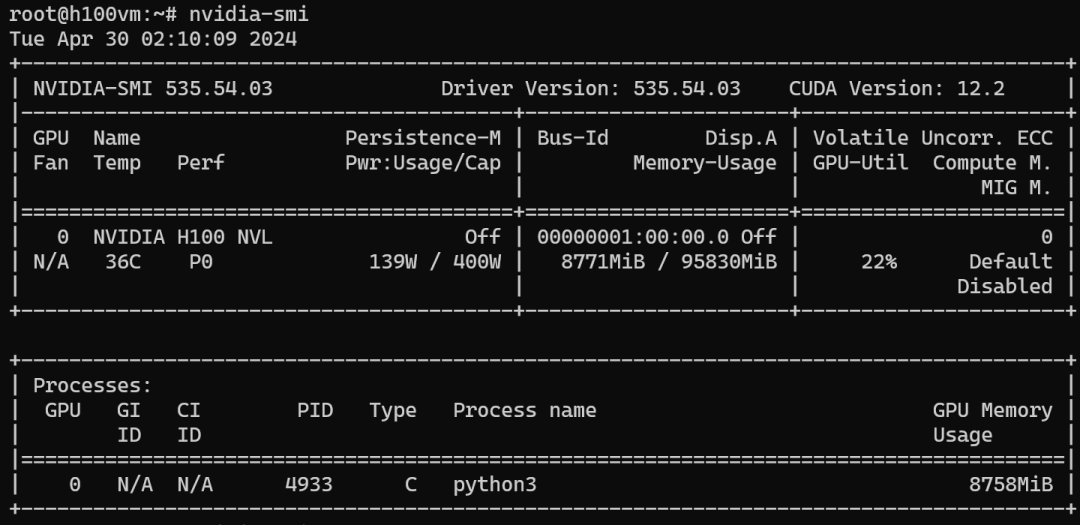
资源利用率如下:
使用相同的prompt和超参,换一个模型ponyFaetality_v11.safetensors,生成的结果如下:

根据图生图,给原图女孩增加一顶红色的帽子:

接下来,定位置修图,将帽子换成黄色(我故意把mask的图留一点红边以验证像素的准确性)。
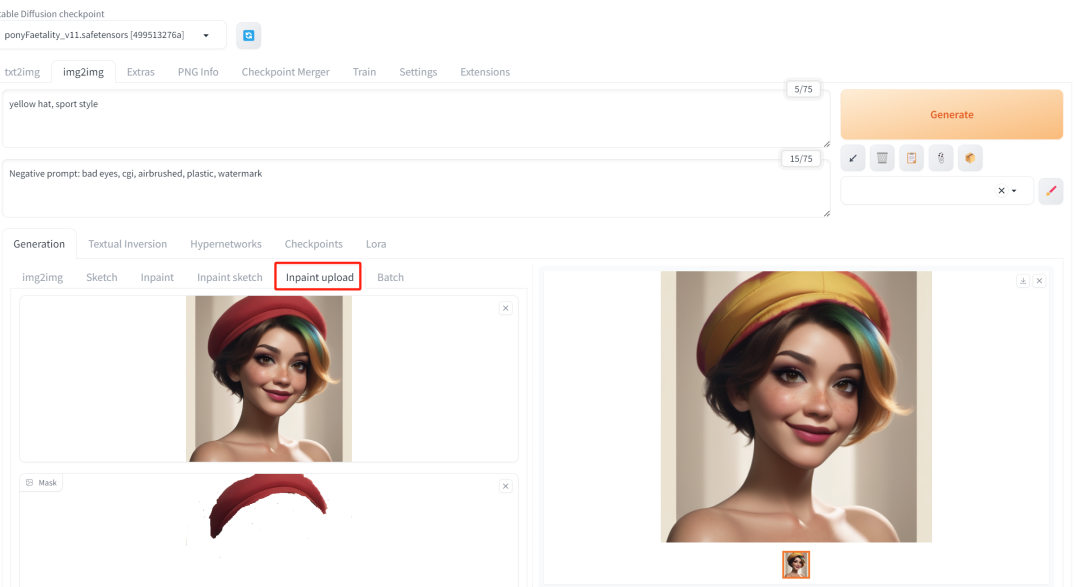
效果很不错。
下一篇验证LoRA的效果。