机器学习or深度学习?
“ 其实本篇文章讲的是ArcGIS应用于机器学习方向上的两个模型。一个深度学习算法模型:FullyConnectedNetwork,一个机器学习算法模型(模型集):MLModel。温馨提示:内容较多,请耐心食用。”
还是老一套,先说思路:背景介绍 -> 数据集探索分析 -> FullyConnectedNetwork -> MLModel -> 总结
01
—
背景介绍
有一个朋友一直问我(此朋友不是虚构的),深度学习与机器学习到底有什么区别?同样机器学习做的事情,深度学习去训练不废时间么?为什么选择深度学习?
emmm,第一时刻我是被问懵的,这可咋忽悠,啊不,咋科普。首先,我们都知道深度学习就是机器学习的分支,那深度学习的深是什么意思呢?我们以简单的深度学习模型为例:

上图中的模型经过了一个三个Linear()操作,那在机器学习中一个Linear()就相当于机器学习中一个线性回归模型了,所以深度学习中的深是因为模型层数很深 。
。
另外,在之前的文章ArcGIS API for Python:深度学习模块概览中提到了两个模型:

其中FullyConnectedNetwork是深度学习算法模型,而MLModel是机器学习算法模型。那不正好,拿这俩模型以及波士顿房价预测案例来对比一下深度学习与机器学习。
那就,开搞!
02
—
数据集探索分析
在机器学习方向上,数据集的探索分析尤为重要,以为只有了解数据的情况才能知道自己该使用什么模型、如何预处理数据来提高模型精度。本文会带大家简单探索分析一下,过一把数据分析师的瘾。
首先加载数据集
# 导包%matplotlib inlineimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom IPython.display import Image, HTMLfrom arcgis.learn import FullyConnectedNetwork, MLModel, prepare_tabulardatafrom sklearn.datasets import load_bostonfrom sklearn.preprocessing import StandardScaler
# 加载数据并转换成dataframeboston_dataset = load_boston()target = boston_dataset['target'].reshape(506,1)boston_df = pd.DataFrame(np.hstack((boston_dataset['data'],target)),columns=np.append(boston_dataset['feature_names'],['PRICE']))boston_df
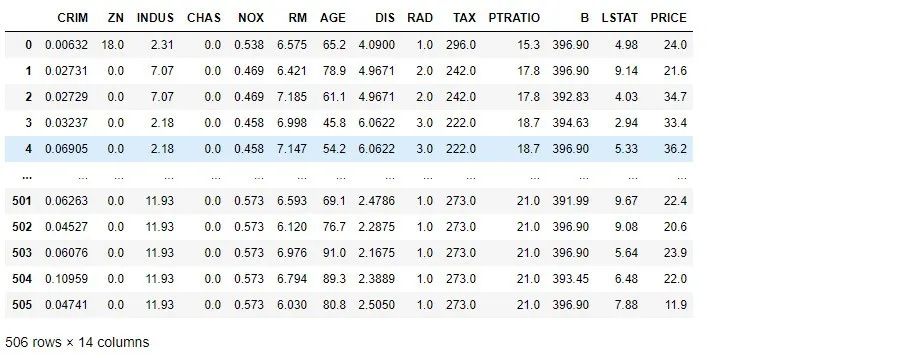
上图中dataframe,除了PRICE那一列为房价之外,其余的全是特征,共13个,释义如下:
查看一下房价分布直方图:
boston_X,boston_Y = load_boston(return_X_y=True)plt.figure()plt.hist(boston_Y,bins=20)plt.show()
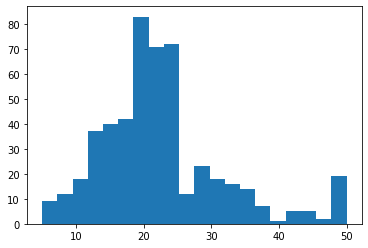
从直方图上可以看出房价大致符合正态分布。然后看一下各列值随ID变化的趋势:
for i in range(0,boston_df.shape[1]):plt.figure(figsize=(20,3))plt.title(boston_df.columns[i])plt.plot(boston_df[boston_df.columns[i]])plt.show()














在上面14张图中,最上面的是房价,从下面的图中找到变化趋势跟第一张图越接近就说明相关性越大。当然除了看趋势之外,还可以直接使用df.corr()函数查看相关性:
corr = boston_df.corr()corr.style.background_gradient(cmap='Greens').set_precision(2)
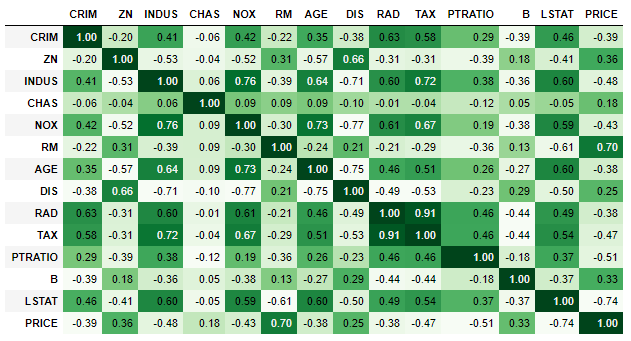
可以看到RM对房价影响最大(0.70),其次是ZN(0.36)。RM代表每栋住宅的房间数,ZN代表着住宅用地所占比例。结合现实生活看的话,好像是那么回事,emmmmm。
那数据探索完了,我们知道数据中没有需要清洗的脏数据,还知道相关性较强的特征貌似有那么两个,后续可能对选模型有帮助。
03
—
FullyConnectedNetwork
了解完数据之后,那不就直接提上模型训练流程:
首先准备数据,划分成训练集与测试集:
train_df = boston_df[:500].copy()# 测试集就6条数据,先看看效果咋样test_df = boston_df[500:].copy()
使用prepare_tabulardata()方法准备数据:
X = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']data = prepare_tabulardata(train_df,val_split_pct=0.2,variable_predict='PRICE',explanatory_variables=X)
参数分别为:dataframe,验证集划分比,预测变量以及解释变量。这个解释变量就是咱们13个特征,很容易理解。
# 查看一个batch的数据data.show_batch()
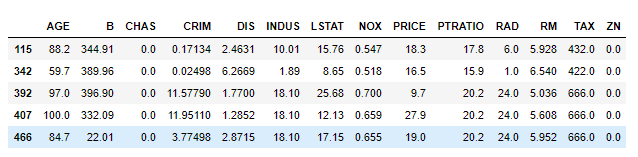
(其实查看不查看,意义不大,毕竟不如计算机视觉中的图片样本看的过瘾 )
)
然后实例化模型,模型训练以及推理
# 实例化模型fcn = FullyConnectedNetwork(data)# 学习率查找lr = fcn.lr_find()lr
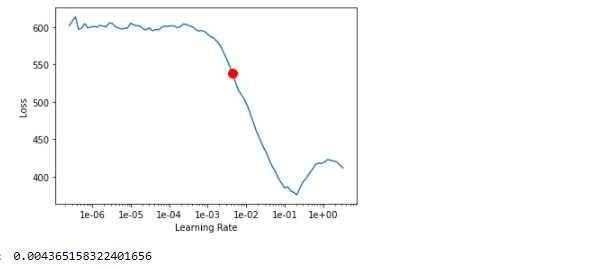
模型训练:
fcn.fit(300,lr)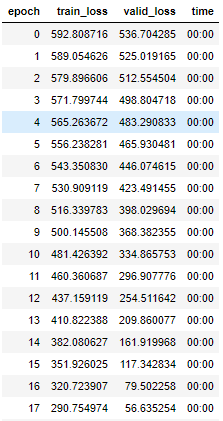
(cv方向上模型训练习惯了,甚至还有点不适应这训练速度,嗖嗖嗖的)
训练结束之后,查看一下loss曲线:
fcn.plot_losses()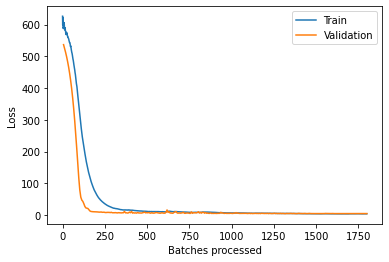
看起来模型拟合的还不错,那就直接看得分吧:
r_Square_fcn_test = fcn.score()print('r_Square_fcn_test: ', round(r_Square_fcn_test,5))
0.92看上去挺不错的样子。哦对了,这个得分计量标准使用的是r2-sorce,在这里面就不详细讲原理公式了,反正就是越高越好。
然后使用测试集测试一下模型效果:
fcn.predict(test_df,prediction_type='dataframe')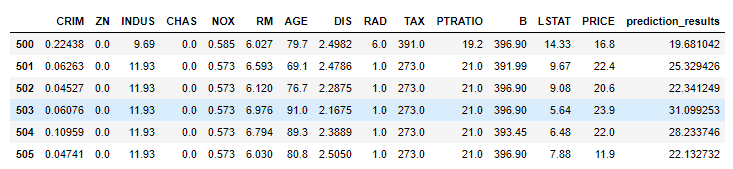
emmmm,貌似看不出来啥啥来,那就整多点数据:
big_test_df = boston_df.sample(100)big_test_prediction_df = fcn.predict(big_test_df,prediction_type='dataframe')big_test_prediction_df
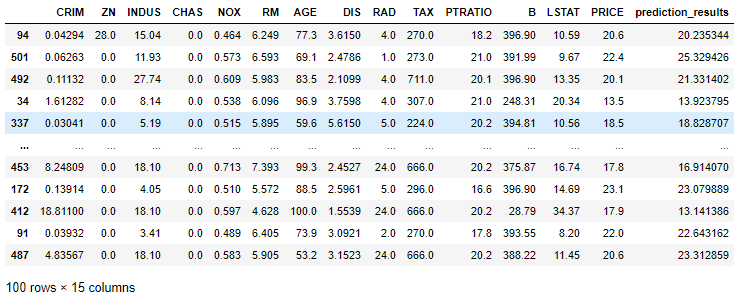
然后再查看一下r2得分:
from sklearn.metrics import r2_scorer2_test = r2_score(big_test_prediction_df['PRICE'],big_test_prediction_df['prediction_results'])print('R-Square: ', round(r2_test, 2))
R-Square: 0.95
得分看起来不错,但是好像不是那么形象。那就画图呗,清晰明了(让我回忆起以前作为一个画图仔的日子):
plot_df = big_test_prediction_df.sort_index(plt.figure(figsize=(30,6))plt.plot(plot_df['PRICE'], linewidth=1, label= 'Actual')plt.plot(plot_df['prediction_results'], linewidth=1, label= 'Predicted')plt.ylabel('price', fontsize=14)plt.legend(fontsize=14,loc='upper right')plt.title('Actual Vs Predicted Price', fontsize=14)plt.grid()plt.show()
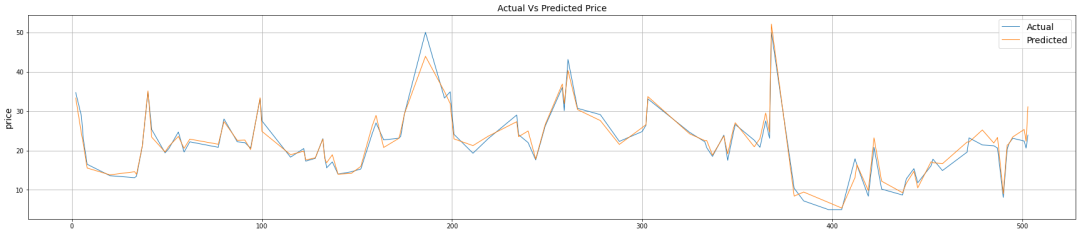
两条曲线越相近那么模型越好。那到这深度学习的算法就试了,下面使用同样的训练集、测试集等数据,尝试一下机器学习的方法。
04
—
MLModel
在模型开始训练之前,咱们得说一下MLModel的独特之处。MLModel从某种意义上说,是sklearn中机器学习模型合计,什么意思呢?我们打开sklearn网站:
https://scikit-learn.org/stable/supervised_learning.html#supervised-learning
可以看到有很多模型,那么这些模型都可以使用MLModel来读取,并进行训练预测等。就很奈斯,有木有?
在模型实例化的时候,可以直接通过下面的示例方式去实例化:

在第二个参数model_type之后可以填上模型对应的一些参数,比如上图中的n_estimators=100, random_state=43都是模型:sklearn.ensemble.GradientBoostingRegressor中的参数。如果不知道怎么设定参数的话,可以不填使用默认值就好。
在了解完MLModel怎么使用之后,还得了解一下,针对不同的数据及任务该选什么样的模型,一般情况下都是参考下图:
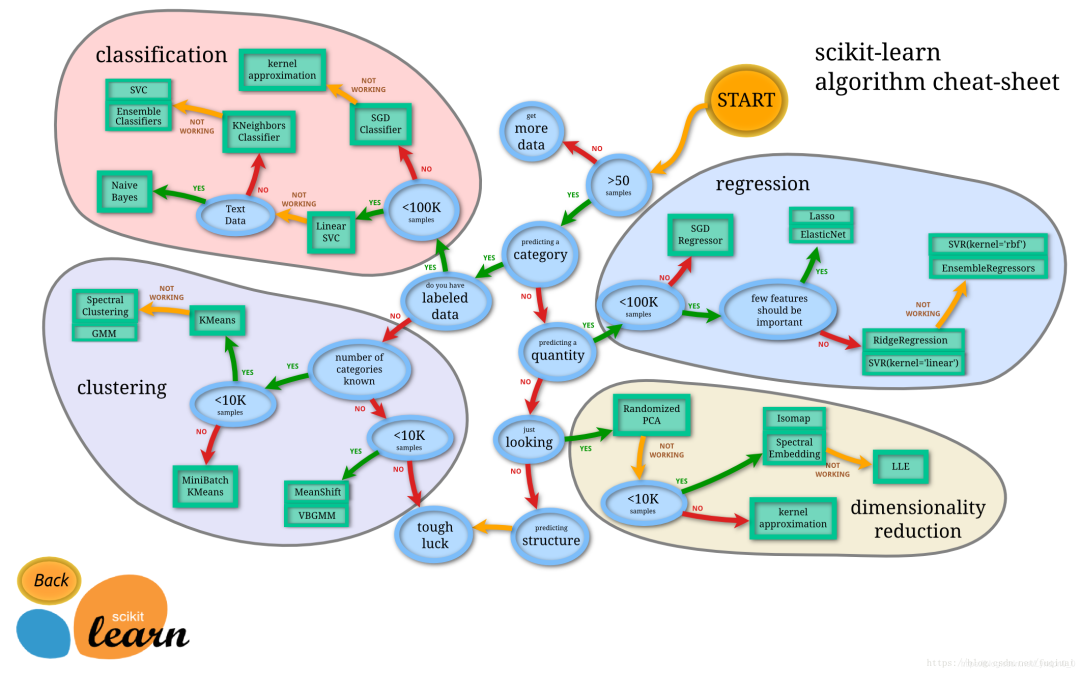
为什么是一般情况下呢,因为我是所有任务相关模型都试一遍,然后选最好的用 ,因为kaggle上有过此类比赛,所以直接问的度娘别人用的都是啥模型。那我试过最好的模型是决策树:sklearn.tree.DecisionTreeRegressor。过程如下:
,因为kaggle上有过此类比赛,所以直接问的度娘别人用的都是啥模型。那我试过最好的模型是决策树:sklearn.tree.DecisionTreeRegressor。过程如下:
实例化模型之前,我们要重新准备数据,给数据添加上标准化处理的过程:
preprocessors = [('CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT',StandardScaler())data = prepare_tabulardata(train_df,"PRICE",explanatory_variables=X,preprocessors=preprocessors)
然后实例化模型、训练:
# 实例化模型model = MLModel(data,'sklearn.tree.DecisionTreeRegressor')# 模型训练model.fit()# 模型得分model.score()
0.7081950576867544
在模型训练完之后,还可以查看模型中特征与房价之间的相关性:
feature_imp_RF = model.feature_importances_rel_feature_imp = 100 * (feature_imp_RF / max(feature_imp_RF))rel_feature_imp = pd.DataFrame({'features':list(X), 'rel_importance':rel_feature_imp })rel_feature_imp = rel_feature_imp.sort_values('rel_importance', ascending=False)plt.figure(figsize=[15,4])plt.yticks(fontsize=10)ax = sns.barplot(x="rel_importance", y="features", data=rel_feature_imp, palette="BrBG")plt.xlabel("Relative Importance", fontsize=10)plt.ylabel("Features", fontsize=10)plt.show()

可以看到,RM相关性最高。然后咱们使用100条数据的测试集重新量化一下精度:
ml_big_test_prediction_df = model.predict(big_test_df,prediction_type='dataframe')ml_r2_test = r2_score(ml_big_test_prediction_df['PRICE'],ml_big_test_prediction_df['prediction_results'])print('R-Square: ', round(ml_r2_test, 2))
R-Square: 0.78
然后可视化,查看模型具体表现情况:
ml_plot_df = ml_big_test_prediction_df.sort_index(plt.figure(figsize=(30,6))plt.plot(ml_plot_df['PRICE'], linewidth=1, label= 'Actual')plt.plot(ml_plot_df['prediction_results'], linewidth=1, label= 'Predicted')plt.ylabel('price', fontsize=14)plt.legend(fontsize=14,loc='upper right')plt.title('Actual Vs Predicted Price', fontsize=14)plt.grid()plt.show()
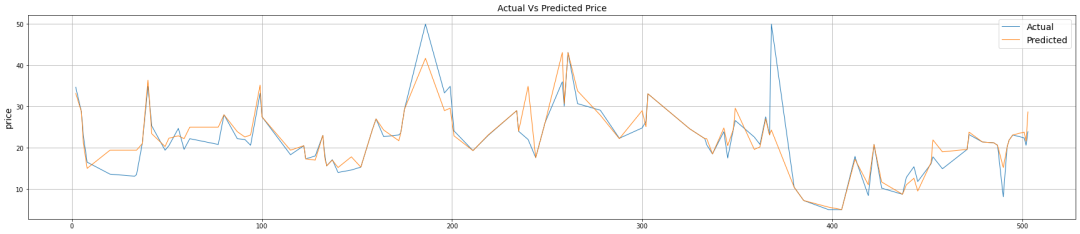
可以明显看出来,两条曲线拟合情况明显没有深度学习算法结果好,只能说是还不错。但是我相信肯定还有提升的空间,只不过我对机器学习不熟 。
。
05
—
总结
从本文中尝试结果上看,深度学习确实会提高模型精度。但是两者本身就不应该在同一个维度去比较,各有各的好处,合适的才是最好的。本文可能有不太严谨的地方,有机器学习的大佬们看到了,一定要与我联系!另外点击文末阅读全文可以查看esri官网的实际案例,思路基本上一致,更好的展示了如何使用MLModel玩转地理数据,强烈建议大家去看看 。
。
本来是要给数读菌投稿的文章,毕竟在他那更有利于知识传播。但是鉴于图与代码都很多,就放弃了 。所以大伙们喜欢的话,就点赞、关注、分享吧!
。所以大伙们喜欢的话,就点赞、关注、分享吧!