AI在医学中的应用逐渐广泛,做一名优秀的跨学科医生需要能读懂AI相关的英文文献,其中的专业用语就非常重要,在此我们开设一个新的专题,介绍AI相关的医学英语。本期将继续介绍机器学习基本流程中特别需要注意的地方。红字单词或短语为了解,划线单词或短语作为识记。
本小节中会出现医生们熟悉的诊断试验的四格表,那么在机器学习领域,这个表格称为什么呢?

Fundamentals of Machine Learning and Deep Learning in Medicine
Reza Borhani, Soheila Borhani, Aggelos K. Katsaggelos
第一章 初步介绍
Chapter 1 Introduction
●主译 Izzy ●审校 Reed
(花哩医学考博专业英语团队原创,禁止转载)
第二节 深入挖掘机器学习流程
A Deeper Dive into the Machine Learning Pipeline
4.重新回顾模型测试Revisiting Model Testing
通过评估图1.6所示的线性分类器的性能,我们可以看到它对测试数据集中的八个样本中的六个进行了正确分类。二者的比值是一个广泛使用的分类质量衡量指标,称为准确性,定义为
By evaluating the performance of the linear classifier shown in Fig. 1.6, we can see that it correctly classifies six of the eight samples in the testing dataset. Dividing the first number by the second gives a widely used quality metric公制的,度量的 for classification called accuracy, defined as
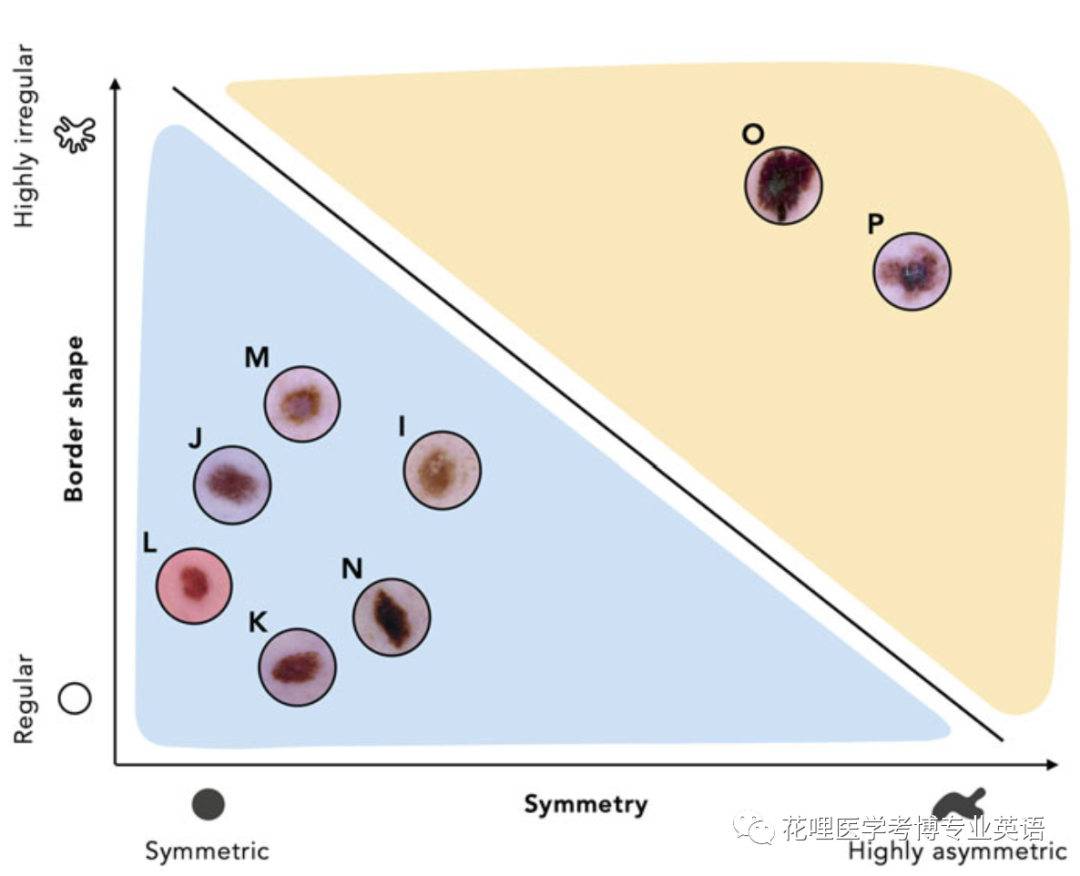
图1.6 八个测试数据点中,有两个数据点的特征出现在线性分类器的错误一侧,这两种恶性病变(M和N)被模型错误地归类为良性
Fig. 1.6 The feature representations of two of the eight testing data points end up on the wrong side of the linear classifier. As a result, these two malignant lesions (M and N) will be classified incorrectly as benign by the model
基于上面给出的定义,准确性的值总是在0和1之间,且越大越好。在我们的示例中,准确性= 6/8 = 0.75。Based on the definition given above, this metric always ranges between 0 and 1, with larger values of it being more desirable令人满意的. In our example, accuracy = 6/8 = 0.75.虽然准确性确实为分类器的总体性能提供了有用的衡量指标,但它并不能区分以下两类错误:将良性病变错误分类为恶性(I型错误)或是将恶性病变错误归类为良性(II型错误)。由于这种区别在医学领域尤为重要,因此通常使用两个额外的指标来报告分类结果。将恶性分类表示为(癌症)阳性记为敏感性,将良性分类表示为阴性记为特异性,这两个指标分别定义为
While accuracy does provide a useful metric for the overall performance of a classifier, it does not distinguish区分 between the misclassification of a benign lesion as malignant (type I error) and the misclassification of a malignant lesion as benign (type II error). Since this distinction区别 is particularly important in the context背景 of medicine, two additional metrics are often used to report classification results. Denoting表明,指代 the malignant class as positive (for cancer) and the benign class as negative, the two metrics of sensitivity and specificity are defined, respectively, as
与准确性一样,敏感性和特异性总是在0和1之间,其值越大越好。在我们的例子中,敏感性=2/4=0.5,特异性=4/4=1。As with accuracy, both sensitivity and specificity always range between 0 and 1, with larger values of them being more desirable. In our example, sensitivity = 2/4 = 0.5 and specificity = 4/4 = 1.目前为止引入的所有三种分类指标(即准确性、敏感性和特异性)都可以使用所谓的混淆矩阵来表达得更精炼、更优雅。如图1.12所示,混淆矩阵是一个简单的查找表,其中分类结果按真值(行)和分类器结果(列)进行分解。All three classification metrics introduced so far到目前为止 (i.e., accuracy, sensitivity, and specificity) can be expressed more compactly紧凑地,小型地 and elegantly using the so-called confusion matrix. As illustrated in Fig. 1.12, a confusion困惑,混淆,混乱局面 matrix is a simple look-up查(表) table where classification results are broken down by ground truth (across rows) and classifier decision (across columns).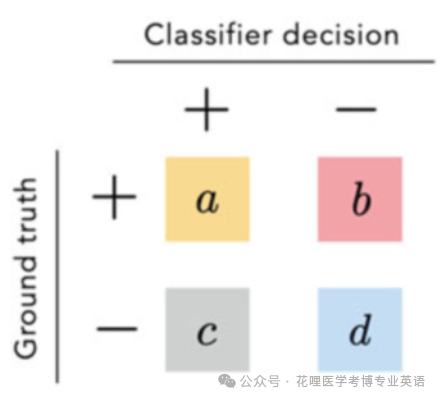
图1.12所示为混淆矩阵。这里,a是被正确地分类为阳性的真阳性数据点的数目,b是被错误地分类为阴性的真阳性数据点数目,c是被不正确地分类成阳性的阴性数据点的数量,并且d是被正确分类成阴性的阴性数据点数目
Fig. 1.12 A confusion matrix illustrated(用示例/图画)说明. Here a is the number of positive data points classified correctly as positive, b is the number of positive data points classified incorrectly as negative, c is the number of negative data points classified incorrectly as positive, and d is the number of negative data points classified correctly as negative
使用混淆矩阵,我们可以将等式(1.3)和(1.4)中的分类度量更简洁地改写为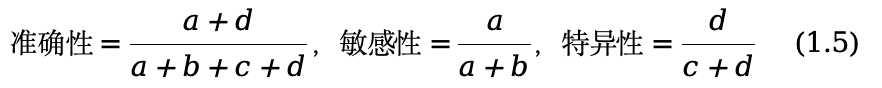
Using the confusion matrix, we can rewrite the classification metrics in Eqs. (1.3) and (1.4) more succinctly简洁地 as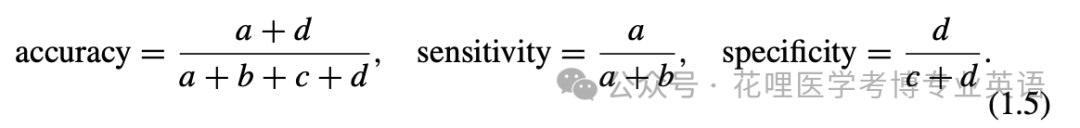
除了等式(1.5)中的度量外,还可以使用混淆矩阵计算许多其他分类度量指标,其中平衡准确性、精确性和F分数(定义如下)在文献中使用更加频繁。
In addition to the metrics in Eq. (1.5), a number of other classification metrics can be calculated using the confusion matrix, among which balanced accuracy, precision, and F-score (as defined below) are more frequently频繁地 used in the literature.下期机器学习与深度学习知识将开启新的一节,介绍机器学习分类法。